Czech Broadcast Conversation MDE Transcripts
| Item Name: | Czech Broadcast Conversation MDE Transcripts |
| Author(s): | Jachym Kolar, Jan Svec |
| LDC Catalog No.: | LDC2009T20 |
| ISBN: | 1-58563-520-0 |
| ISLRN: | 780-971-266-156-8 |
| DOI: | https://doi.org/10.35111/003f-fh25 |
| Release Date: | July 17, 2009 |
| Member Year(s): | 2009 |
| DCMI Type(s): | Text |
| Data Source(s): | broadcast conversation |
| Application(s): | speech recognition, speaker segmentation and tracking, speaker identification, metadata extraction |
| Language(s): | Czech |
| Language ID(s): | ces |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2009T20 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Kolar, Jachym, and Jan Svec. Czech Broadcast Conversation MDE Transcripts LDC2009T20. Web Download. Philadelphia: Linguistic Data Consortium, 2009. |
| Related Works: | View |
Introduction
Czech Broadcast Conversation MDE Transcripts, Linguistic Data Consortium (LDC) catalog number LDC2009T20 and ISBN 1-58563-520-0, was prepared by researchers at the University of West Bohemia, Pilsen, Czech Republic, and consists of approximately 33 hours of transcribed speech from Radioforum, a talk show broadcast on Czech Radio 1. The audio files corresponding to the transcripts in this corpus are contained in Czech Broadcast Conversation Speech (LDC2009S02). These corpora join LDC's other Czech broadcast data sets: Czech Broadcast News Speech (LDC2004S01), Czech Broadcast News Transcripts (LDC2004T01), Voice of America (VOA) Czech Broadcast News Audio (LDC2000S89), and Voice of America (VOA) Czech Broadcast News Transcripts (LDC2000T53).
Czech Broadcast Conversation Speech consists of 72 single channel recordings of Radioforum, a live talk program broadcast by Czech Radio 1 (CRo1) every weekday evening. A total of 40 hours of recordings were collected during the period from February 12, 2003 through June 26, 2003. Individual recordings range from 27 minutes to 36 minutes each. Radioforum's format consists of invited guests (most often politicians) spontaneously answering topical questions posed by one or two interviewers. The number of interviewees in a single program varies from one to three, but typically, one interviewer and two interviewees appear in the program. The material includes passages of interactive dialogue, but longer stretches of monologue-like speech comprise the majority of the collected data. Radioforum also has an interactive segment where listeners call the studio and ask their own questions. That telephony speech was not transcribed in the current release.
Czech Broadcast Conversation MDE Transcripts was created to extend Metadata Extraction (MDE) research to conversational Czech. The goal of MDE is to take raw speech recognition output and refine it into forms that are of more use to humans and to downstream automatic processes. In simple terms, this means the creation of automatic transcripts that are maximally readable. This readability might be achieved in a number of ways: removing non-content words like filled pauses and discourse markers from the text; removing sections of disfluent speech; and creating boundaries between natural breakpoints in the flow of speech so that each sentence or other meaningful unit of speech might be presented on a separate line within the resulting transcript. Natural capitalization, punctuation and standardized spelling, plus sensible conventions for representing speaker turns and identity are further elements in the readable transcript.
The transcripts and annotations in this corpus are stored in three different formats: TRS (Transcriber - http://trans.sourceforge.net), QAn (Quick Annotator - http://www.mde.zcu.cz/qan.html), and RTTM. TRS represents a standard speech transcript. QAn and RTTM contain essentially identical information about structural metadata (MDE); the main difference between them is formatting. Character encoding in all files is ISO-8859-2.
All filenames have the form rfYYMMDD.format where "rf" stands for Radioforum, the following six digits indicate the date of broadcast, and the extension ".format" corresponds to the data format of the particular file ".trs", ".qan", or ".rttm".
More information can be found on the website Structural Metadata Annotation for Czech.
Data
The radio programs recorded for this corpus were transcribed with two purposes. First, in order to produce precise time-aligned verbatim transcripts of the audio recordings, manual transcripts were created using guidelines based on those employed in Czech Broadcast News Transcripts (LDC2004T01). Second, the transcripts were annotated wiith MDE markup to provide structural information about the conversations.
Manual time-aligned verbatim transcription
The original guidelines for time-aligned verbatim transcription used for the Czech broadcast news data were adjusted to better accommodate specifics of the recorded broadcast coversation. Those revised guidelines instructed annotators how to deal with the following phenomena, among others:
- Speaker turns: a corresponding time stamp and speaker ID are inserted every time there is a speaker change in the audio.
- Turn-internal breakpoints: to break up long turns, breakpoints roughly corresponding to 'sentence' boundaries within a speaker turn are inserted.
- Overlapping speech: an overlapping speech region is recognized when more than one speaker talks simultaneously; within this region, each speaker's speech is transcribed separately (if intelligible).
- Background noises: [NOISE] tags are used to mark noticeable background noises.
- Speaker noises: speaker-produced noises are identified with one of the following tags: [BREATH], [COUGH], [LAUGH], [LIP-SMACK].
- Filled pauses: filled pauses produced by a speaker to indicate hesitation or to maintain control of a conversation are transcribed either as [EE-HESITATION] or as [MM-HESITATION], based on their pronunciation.
- Interjections: certain interjections typically used as back channels or to express speaker's agreement or disagreement are transcribed using the [HM] (agreement) and [MH] (disagreement) tags.
- Unintelligible speech: regions of unintelligible speech are marked with a special symbol.
- Numbers: all numerals are transcribed as complete words.
- Mispronounced words: mispronounced words (reading errors, slips of the tongue) are transcribed in the spelling corresponding to their pronunciation in the audio (i.e., the incorrect pronunciation is represented) and marked with a special symbol.
- Word fragments: the pronounced part of the word is transcribed and a single dash is used to indicate point at which word was broken on.
- Punctuation: standard punctuation (limited to commas, periods, and question marks) is used to enhance transcript readability.
Because the verbatim transcripts were created by a large number of annotators, they were manually revised for maximum correctness and consistency.
MDE annotation
MDE is an annotation task which annotates Edit Disfluencies (repetitions, revisions, restarts and complex disfluencies), Fillers (including, e.g., filled pauses and discourse markers) and SUs, or syntactic/semantic units. Originally, the structural MDE annotation standard was defined for English. When developing structural metadata annotation guidelines for Czech, the guidelines developed by LDC for English were followed to the extent possible. Lanaguage-dependent modifications were made based on the description of the syntax of Czech compound and complex sentences. MDE Annotation marks the following phenomena:
- Edit Disfluencies: Edit disfluencies, or speech repairs, occur when speakers correct or alter their utterances or abandon them entirely and start over.
- Fillers: While the term filler has traditionally been synonymous with filled pause, SimpleMDE uses the term to encompass a broad set of vocalized space-fillers: filled pauses (FPs), discourse markers (DMs), explicit editing terms (EETs) and asides/parentheticals (A/Ps).
- Sentence-like units: One of the goals of MDE annotation is the identification of all units within the discourse that function to express a complete thought or idea on the part of the speaker.Within MDE these elements are called SUs (Syntactic, Semantic or Slash Units).
Corpus Statistics
The table below contains details about the audio files and the transcripts:
| Number of shows | 72 |
| Number of word tokens | 292.6k |
| Number of unique words | 30.5k |
| Duration of transcribed speech | 33.0h |
| Total number of speakers | 128 |
| Male speakers | 108 |
| Female speakers | 20 |
Samples
The Czech Broadcast Conversation MDE Transcripts employs three transcription formats. A sample of each is included below.
- TRS-Transcriber-Provides basic transcription of speech.
- QAN-Quick Annotator, the annotation format used to provide structural metadata.
- RTTM These annotations provide structural metadata using a format similar EARS MDE.
{kind=link}
{kind=link}
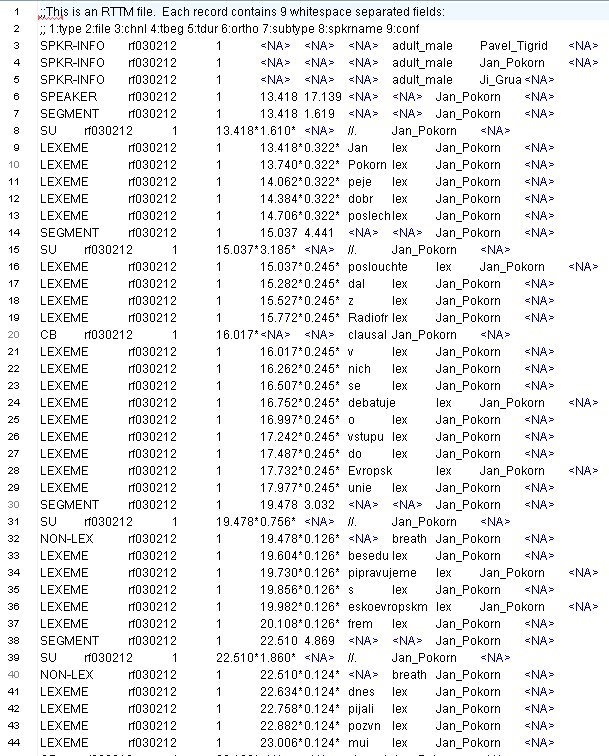{kind=link}
Sponsorship
The completion of this corpus was facilitated by funding provided by the Ministry of Education of the Czech Republic under projects No. ME909 and 2C06020.