USC-SFI MALACH Interviews and Transcripts Czech
| Item Name: | USC-SFI MALACH Interviews and Transcripts Czech |
| Author(s): | Josef V. Psutka, Josef Psutka, Radová Vlasta, Pavel Ircing, Matoušek Jindřich, Müller Luděk |
| LDC Catalog No.: | LDC2014S04 |
| ISBN: | 1-58563-672-X |
| ISLRN: | 310-213-848-753-5 |
| DOI: | https://doi.org/10.35111/v2nt-7j09 |
| Release Date: | March 16, 2014 |
| Member Year(s): | 2014 |
| DCMI Type(s): | Sound, Text |
| Sample Type: | pcm |
| Sample Rate: | 16000 |
| Data Source(s): | field recordings |
| Project(s): | MALACH |
| Application(s): | speech recognition, sociolinguistics |
| Language(s): | Czech |
| Language ID(s): | ces |
| License(s): |
USC-SFI MALACH Interviews and Transcripts Czech For-Profit USC-SFI MALACH Interviews and Transcripts Czech Non-Member USC-SFI MALACH Interviews and Transcripts Czech Not-for-Profit |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Psutka, Josef V., et al. USC-SFI MALACH Interviews and Transcripts Czech LDC2014S04. Web Download. Philadelphia: Linguistic Data Consortium, 2014. |
| Related Works: | View |
Introduction
USC-SFI MALACH Interviews and Transcripts Czech was developed by The University of Southern California Shoah Foundation Institute (USC-SFI) and the University of West Bohemia as part of the MALACH (Multilingual Access to Large Spoken ArCHives) Project. It contains approximately 229 hours of interviews from 420 interviewees along with transcripts and other documentation.
Inspired by his experience making Schindlers List, Steven Spielberg established the Survivors of the Shoah Visual History Foundation in 1994 to gather video testimonies from survivors and other witnesses of the Holocaust. While most of those who gave testimony were Jewish survivors, the Foundation also interviewed homosexual survivors, Jehovahs Witness survivors, liberators and liberation witnesses, political prisoners, rescuers and aid providers, Roma and Sinti (Gypsy) survivors, survivors of eugenics policies, and war crimes trials participants. The Foundation’s Visual History Archive holds nearly 55,000 video testimonies in 43 languages, representing 65 countries; it is the largest archive of its kind in the world. In 2006, the Foundation became part of the Dana and David Dornsife College of Letters, Arts and Sciences at the University of Southern California in Los Angeles and was renamed as the USC Shoah Foundation Institute for Visual History and Education.
The goal of the MALACH project was to develop methods for improved access to large multinational spoken archives. The focus was advancing the state of the art of automatic speech recognition and information retrieval. The characteristics of the USC-SFI collection -- unconstrained, natural speech filled with disfluencies, heavy accents, age-related coarticulations, un-cued speaker and language switching and emotional speech -- were considered well-suited for that task. The work centered on five languages: English, Czech, Russian, Polish and Slovak. USC-SFI MALACH Interviews and Transcripts Czech was developed for the Czech speech recognition experiments.
LDC has also released USC-SFI MALACH Interviews and Transcripts English (LDC2012S05).
Data
The speech data in this release was collected beginning in 1994 under a wide variety of conditions ranging from quiet to noisy (e.g., airplane overflights, wind noise, background conversations and highway noise). Original interviews were recorded on Sony Beta SP tapes, then digitized into a 3 MB/s MPEG-1 stream with 128 kb/s (44 kHz) stereo audio. The sound files in this release are single channel FLAC compressed PCM WAV format at a sampling frequency of 16 kHz.
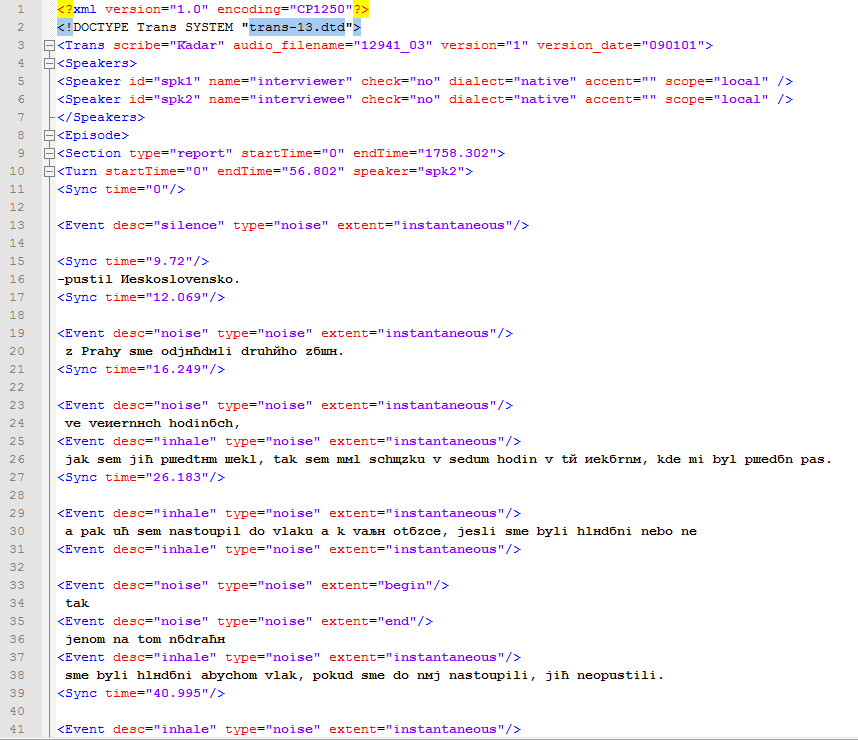
Approximately 570 of all USC-SFI collected interviews are in Czech and average approximately 2.25 hours each. The interviews sessions in this release are divided into a training set (400 interviews) and a test set (20 interviews). The first fifteen minutes of the second tape from each training interview (approximately 30 total minutes of speech) were transcribed in .trs format using Transcriber 1.5.1. The test interviews were transcribed completely. Thus the corpus consists of 229 hours of speech (186 hours of training material plus 43 hours of test data) with 143 hours transcribed (100 hours of training material plus 43 hours of test data). Certain interviews include speech from family members in addition to that of the subject and the interviewer. Accordingly, the corpus contains speech from more than 420 speakers, who are more or less equally distributed between males and females.
Samples
Please view this audio sample and transcript .
{kind=link}
Updates
None at this time.
Copyright
Portions © 2014 USC Shoah Foundation Institute, © 2014 Trustees of the University of PennsylvaniaThis USC SFI Malach Data is from the archive of the University of Southern California Shoah Foundation Institute for Visual History and Education