GALE Phase 1 Chinese Broadcast News Parallel Text - Part 3
| Item Name: | GALE Phase 1 Chinese Broadcast News Parallel Text - Part 3 |
| Author(s): | Xiaoyi Ma, Stephanie Strassel |
| LDC Catalog No.: | LDC2008T18 |
| ISBN: | 1-58563-489-1 |
| ISLRN: | 579-080-587-850-3 |
| DOI: | https://doi.org/10.35111/gfgm-vw13 |
| Release Date: | September 15, 2008 |
| Member Year(s): | 2008 |
| DCMI Type(s): | Text |
| Data Source(s): | transcribed speech, broadcast news |
| Project(s): | GALE |
| Application(s): | machine translation |
| Language(s): | English, Mandarin Chinese |
| Language ID(s): | eng, cmn |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2008T18 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Ma, Xiaoyi, and Stephanie Strassel. GALE Phase 1 Chinese Broadcast News Parallel Text - Part 3 LDC2008T18. Web Download. Philadelphia: Linguistic Data Consortium, 2008. |
| Related Works: | View |
Introduction
GALE Phase 1 Chinese Broadcast News Parallel Text - Part 3 contains transcripts and English translations of 19.1 hours of Chinese broadcast news programming from Voice of America (VOA), China Central TV (CCTV) and Phoenix TV. GALE Phase 1 Chinese Broadcast News Parallel Text - Part 3 is the last of the three-part GALE Phase 1 Chinese Broadcast News Parallel Text, which, along with other corpora, was used as training data in year 1 (Phase 1) of the DARPA-funded GALE program. LDC has previously released GALE Phase 1 Chinese Broadcast News Parallel Text - Part 1 and GALE Phase 1 Chinese Broadcast News Parallel Text - Part 2.
Source Data
A total of 19.1 hours of Chinese broadcast news recordings were selected from three sources: VOA, CCTV (a broadcaster from Mainland China) and Phoenix TV (a Hong Kong-based satellite TV station). The transcripts and translations represent recordings of five different programs.
A manual selection procedure was used to choose data appropriate for the GALE program, namely, news programs focusing on current events. Stories on topics such as sports, entertainment and business were excluded from the data set. The following table is a summary of the files included in this release.
| Source | Program | Epoch (YYYY.MM) | #hours | #characters |
| VOA | VOA Mandarin | 1997.05.20 and 1997.06.18 | 2.0 | 25,051 |
| CCTV | CCTV4 Daily News | 2005.11-2006.01 | 4.8 | 57,376 |
| CCTV4 News3 | 2005.05-2006.01 | 2.6 | 33,361 | |
| Phoenix TV | Global Report | 2005.10-2005.12 | 5.9 | 61,339 |
| Good Morning China | 2005.12-2006.01 | 3.8 | 48,976 |
The VOA files are named mv970520c.tdf and mv970618a.tdf. The corresponding speech recordings for the VOA data can be found in 1997 Mandarin Broadcast News Speech (HUB4-NE), LDC98S73.
Transcription
The selected audio snippets were carefully transcribed by LDC annotators and professional transcription agencies following LDC's Quick Rich Transcription specification. Manual sentence units/segments (SU) annotation was also performed as part of the transcription task. Three types of end of sentence SU are identified: (1) statement SU, (2) question SU and (3) incomplete SU.
Translation
After transcription and SU annotation, files were reformatted into a human-readable translation format and assigned to professional translators for careful translation. Translators followed LDC's GALE Translation guidelines, which describe the makeup of the translation team, the source data format, the translation data format, best practices for translating certain linguistic features (such as names and speech disfluencies) and quality control procedures applied to completed translations.
TDF Format
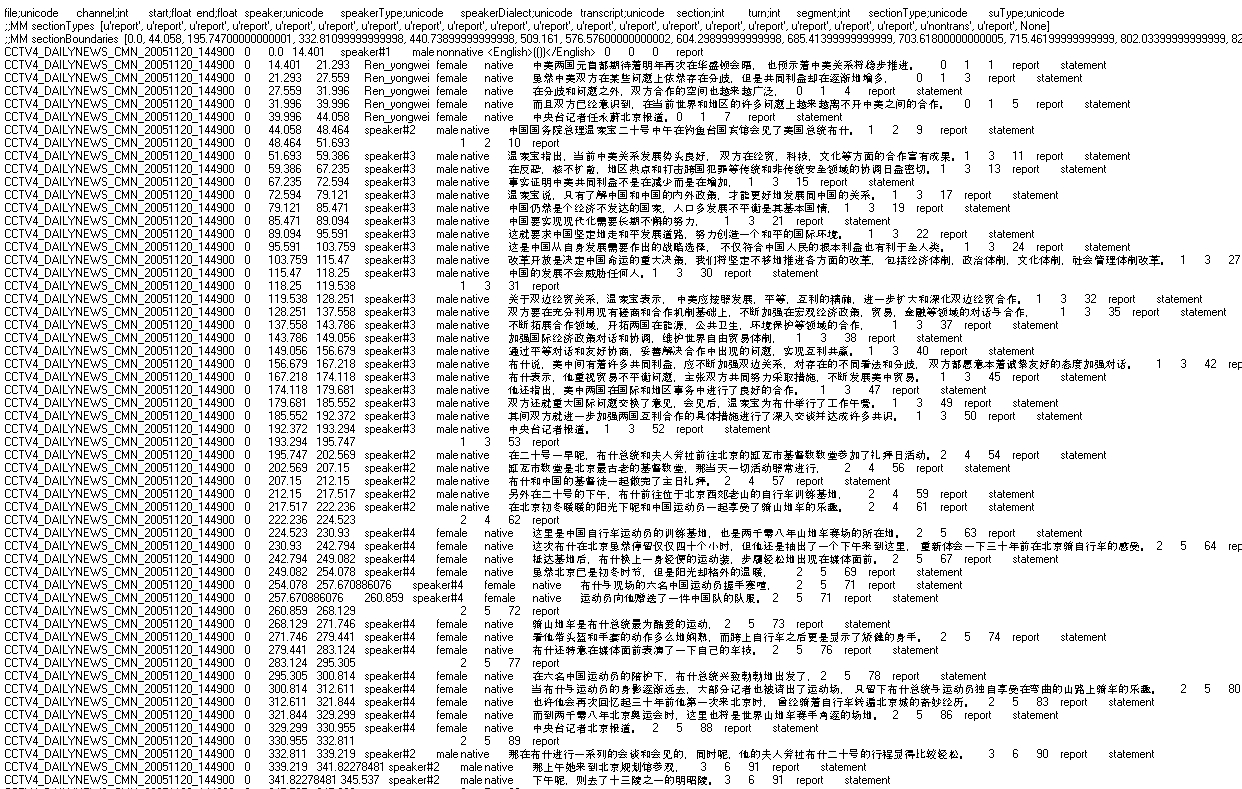
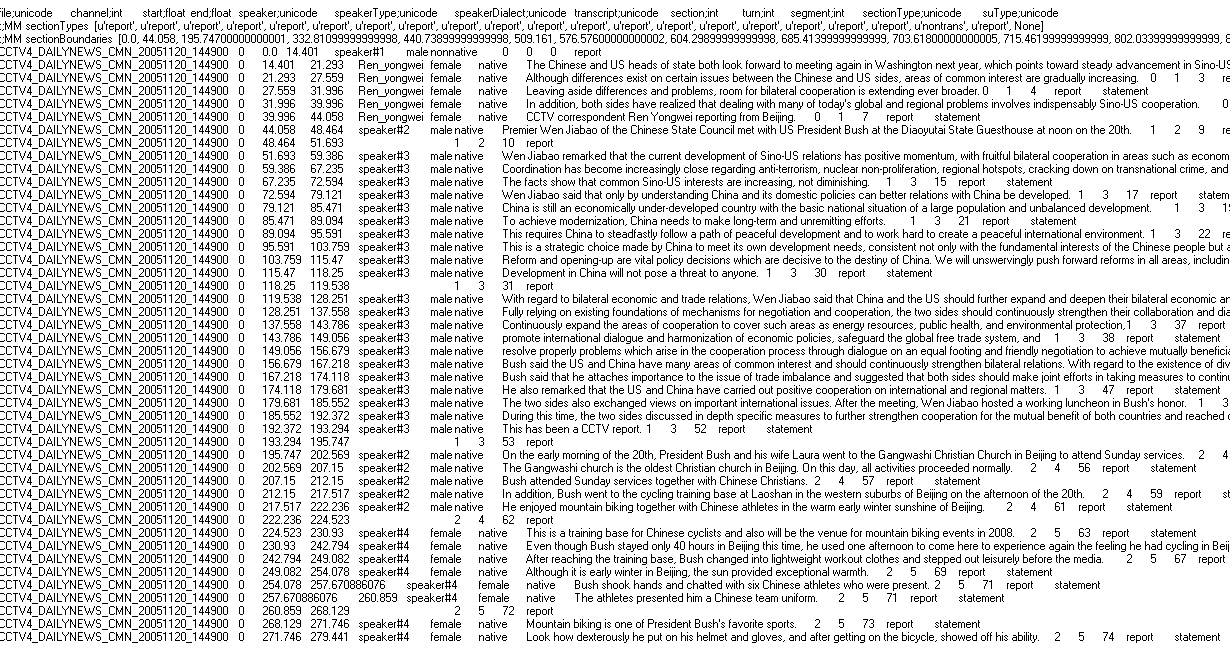
All final data are in Tab Delimited Format (TDF). TDF is compatible with other transcription formats, such as the Transcriber format and AG format, and it is easy to process.
Each line of a TDF file corresponds to a speech segment and contains 13 tab delimited fields: field data_type; file; channel int; start float; end float; speaker; speakerType; speakerDialect; transcript; section int; turn int; segment int; sectionType; and suType.
A source TDF file and its translation are the same except that the transcript in the source TDF is replaced by its English translation.
Sponsorship
This work was supported in part by the Defense Advanced Research Projects Agency, GALE Program Grant No. HR0011-06-1-0003. The content of this publication does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.
Samples
For an example of the data in this corpus, please examine these sample source and translation files.
{kind=link}
{kind=link}