GALE Phase 2 Arabic Broadcast Conversation Transcripts Part 1
| Item Name: | GALE Phase 2 Arabic Broadcast Conversation Transcripts Part 1 |
| Author(s): | Meghan Glenn, Haejoong Lee, Stephanie Strassel, Kazuaki Maeda |
| LDC Catalog No.: | LDC2013T04 |
| ISBN: | 1-58563-637-1 |
| ISLRN: | 418-297-555-875-4 |
| DOI: | https://doi.org/10.35111/hqke-qv38 |
| Release Date: | February 15, 2013 |
| Member Year(s): | 2013 |
| DCMI Type(s): | Text |
| Data Source(s): | broadcast conversation |
| Project(s): | GALE |
| Application(s): | speech recognition |
| Language(s): | Standard Arabic |
| Language ID(s): | arb |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2013T04 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Glenn, Meghan, et al. GALE Phase 2 Arabic Broadcast Conversation Transcripts Part 1 LDC2013T04. Web Download. Philadelphia: Linguistic Data Consortium, 2013. |
| Related Works: | View |
Introduction
GALE Phase 2 Arabic Broadcast Conversation Transcripts Part 1 was developed by the Linguistic Data Consortium (LDC) and contains transcriptions of approximately 123 hours of Arabic broadcast conversation speech collected in 2006 and 2007 by LDC, MediaNet, Tunis, Tunisia and MTC, Rabat, Morocco during Phase 2 of the DARPA GALE (Global Autonomous Language Exploitation) program. Corresponding audio data is released as GALE Phase 2 Arabic Broadcast Conversation Speech Part 1 (LDC2013S02).
The source broadcast conversation recordings feature interviews, call-in programs and round table discussions focusing principally on current events from the following sources: Al Alam News Channel, based in Iran, Al Arabiya, a news television station based in Dubai, Aljazeera, a regional broadcaster located in Doha, Qatar, Al Ordiniyah, a national broadcast station in Jordan, Lebanese Broadcasting Corporation, a Lebanese television station, Nile TV, a broadcast programmer based in Egypt, Oman TV, a national broadcaster located in the Sultanate of Oman, Saudi TV, a national television station based in Saudi Arabia and Syria TV, the national television station in Syria.
Data
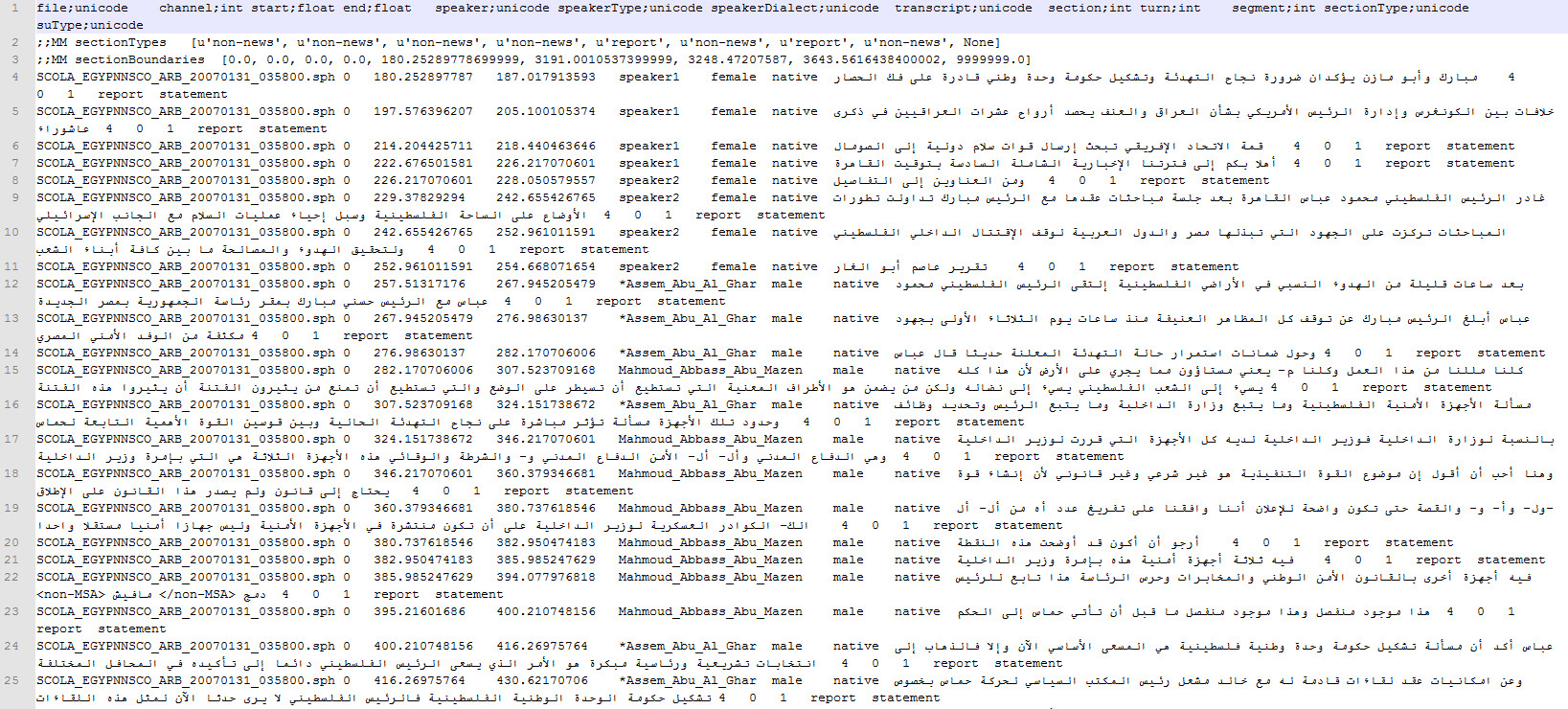
The transcript files are in plain-text, tab-delimited format (TDF) with UTF-8 encoding, and the transcribed data totals 752,747 tokens. The transcripts were created with the LDC-developed transcription tool, XTrans, a multi-platform, multilingual, multi-channel transcription tool that supports manual transcription and annotation of audio recordings. XTrans is available from the following link, http://www.ldc.upenn.edu/tools/XTrans/downloads/.
The files in this corpus were transcribed by LDC staff and/or by transcription vendors under contract to LDC. Transcribers followed LDCs quick transcription guidelines (QTR) and quick rich transcription specification (QRTR) both of which are included in the documentation with this release. QTR transcription consists of quick (near-)verbatim, time-aligned transcripts plus speaker identification with minimal additional mark-up. It does not include sentence unit annotation. QRTR annotation adds structural information such as topic boundaries and manual sentence unit annotation to the core components of a quick transcript. Files with QTR as part of the filename were developed using QTR transcription. Files with QRTR in the filename indicate QRTR transcription.
Samples
Please view this sample.
{kind=link}
Updates
None at this time.
Acknowledgement
This work was supported in part by the Defense Advanced Research Projects Agency, GALE Program Grant No. HR0011-06-1-0003. The content of this publication does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.