Manually Annotated Sub-Corpus Third Release
| Item Name: | Manually Annotated Sub-Corpus Third Release |
| Author(s): | Nancy Ide, Keith Suderman, Collin Baker, Rebecca Passonneau, Christiane Fellbaum |
| LDC Catalog No.: | LDC2013T12 |
| ISBN: | 1-58563-647-9 |
| ISLRN: | 021-129-973-518-8 |
| DOI: | https://doi.org/10.35111/ctg7-5698 |
| Release Date: | July 17, 2013 |
| Member Year(s): | 2013 |
| DCMI Type(s): | Text |
| Data Source(s): | weblogs, web collection, transcribed speech, telephone speech, newswire, journal entries, government documents, fiction, email |
| Project(s): | American National Corpus (ANC) |
| Application(s): | natural language processing |
| Language(s): | English |
| Language ID(s): | eng |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2013T12 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Ide, Nancy, et al. Manually Annotated Sub-Corpus Third Release LDC2013T12. Web Download. Philadelphia: Linguistic Data Consortium, 2013. |
| Related Works: | View |
Introduction
Manually Annotated Sub-Corpus (MASC) Third Release was developed as part of The American National Corpus project and consists of approximately 500,000 words of contemporary American English written and spoken data annotated for a wide variety of linguistic phenomena.
The MASC project was established to address, to the extent possible, many of the obstacles to the creation of large-scale, robust, multiply-annotated corpora of English covering a wide range of genres of written and spoken language data. The project provides appropriate data and annotations to serve as the base for a community-wide annotation effort, together with an infrastructure that enables the incorporation of contributed annotations into a single, usable format that can then be analyzed as it is or transduced to any of a variety of other formats. The aim is to offset some of the high costs of producing high quality linguistic annotations via a distribution of effort and to solve some of the usability problems for annotations produced at different sites by harmonizing their representation formats. It also provides data from a much wider variety of genres than are often present in existing multiply-annotated corpora of English, and all of the data in the corpus are drawn from current American English so as to be most useful for natural language processing applications used in the web-based environment. Further information about the pojrect is available at the MASC website.
The source texts were drawn from the open portion of the American National Corpus Second Release, which includes written texts and spoken transcripts of American English from a broad range of genres produced since 1990 and from the Language Understanding Annotation Corpus, a collection of various genres inlcuding broadcast, newswire, email, and telephone speech annotated for committed belief, event and entity coreference, dialog acts and temporal relations.
MASC Third Release includes the the contents of MASC First Release (LDC2010T22) (82,000 words) which is also available from LDC. There is no second release.
Data
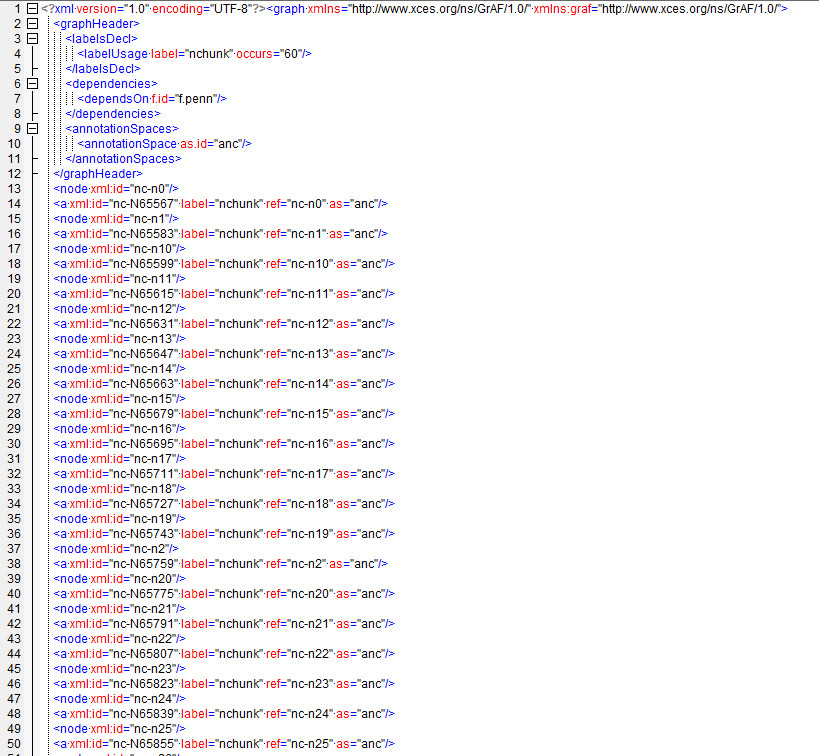
All data in this release was annotated for logical structure (paragraph, headings, etc.), token and sentence boundaries, part of speech and lemma, shallow parse (noun and verb chunks) and named entities (person, organization, location and date). Portions of the corpus were also annotated for FrameNet frames (40k full text), Penn Treebank syntax (82k) and opinion (50k). All annotations were either manually produced or hand-validated and represented in ISO-GrAF standoff format. The original texts were derived from original electronic versions in a wide variety of formats, including but not limited to Quark Express, XML, Microsoft Word, Portable Document Format (PDF), HTML, and plain text. Transduction procedures varied depending on the original format.
As little correction or other editorial modification as possible was applied to the text. Corrections to the text were either made in standoff documents containing the corrected version or were reflected in values of segmentation, token, sentence, or other segmental unit, and/or part of speech annotation.
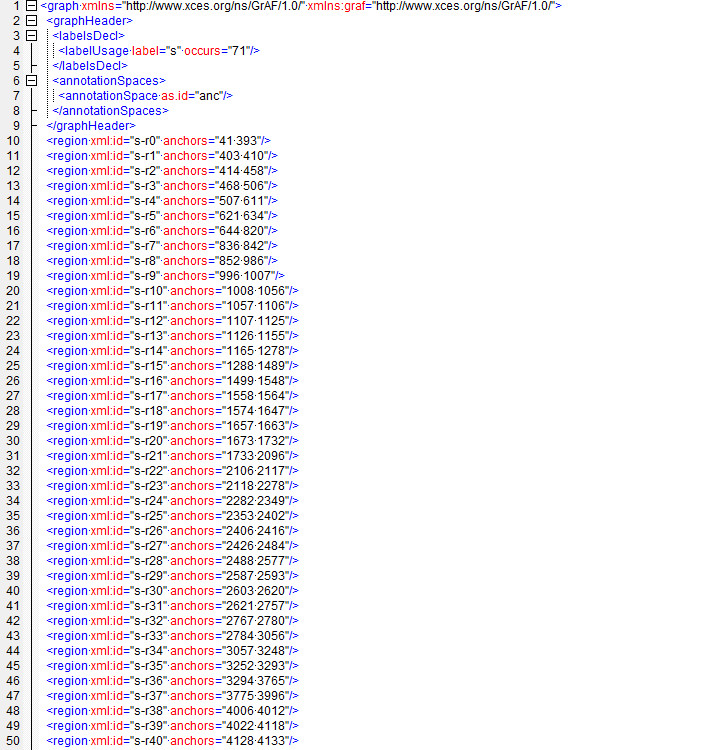
The data are segmented into minimal regions spanning the primary data. Minimal regions are identified as the smallest unit any of the tokenizations applied to data references. Token annotations reference these regions as appropriate. Sentences reference regions in primary data.
Samples
Please consult this email sample and telephone sample.
{kind=link}
{kind=link}
Updates
None at this time.