The Subglottal Resonances Database
| Item Name: | The Subglottal Resonances Database |
| Author(s): | Abeer Alwan, Steven M. Lulich, Mitchell S. Sommers |
| LDC Catalog No.: | LDC2015S03 |
| ISBN: | 1-58563-711-4 |
| ISLRN: | 022-705-777-770-6 |
| DOI: | https://doi.org/10.35111/5wf0-c349 |
| Release Date: | April 20, 2015 |
| Member Year(s): | 2015 |
| DCMI Type(s): | Sound, StillImage, Text |
| Sample Type: | flac |
| Sample Rate: | 48000 |
| Data Source(s): | microphone speech |
| Application(s): | speech recognition |
| Language(s): | English |
| Language ID(s): | eng |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2015S03 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Alwan, Abeer, Steven Lulich, and Mitchell Sommers. The Subglottal Resonances Database LDC2015S03. Web Download. Philadelphia: Linguistic Data Consortium, 2015. |
| Related Works: | View |
Introduction
The Subglottal Resonances Database was developed by Washington University and University of California Los Angeles and consists of 45 hours of simultaneous microphone and subglottal accelerometer recordings of 25 adult male and 25 adult female speakers of American English between 22 and 25 years of age.
The subglottal system is composed of the airways of the tracheobronchial tree and the surrounding tissues. It powers airflow through the larynx and vocal tract, allowing for the generation of most of the sound sources used in languages around the world. The subglottal resonances (SGRs) are the natural frequencies of the subglottal system. During speech, the subglottal system is acoustically coupled to the vocal tract via the larynx. SGRs can be measured from recordings of the vibration of the skin of the neck during phonation by an accelerometer, much like speech formants are measured through microphone recordings.
SGRs have received attention in studies of speech production, perception and technology. They affect voice production, divide vowels and consonants into discrete categories, affect vowel perception and can be useful in automatic speech recognition.
Data
Speakers were recruited by Washington University's Psychology Department. The majority of the participants were Washington University students who represented a wide range of American English dialects, although most were speakers of the mid-American English dialect.
The corpus consists of 35 monosyllables in a phonetically neutral carrier phrase (“I said a ____ again”), with 10 repetitions of each word by each speaker, resulting in 17,500 individual microphone (and accelerometer) waveforms. The monosyllables were comprised of 14 hVd words and 21 CVb words where C was b,d, g and V included all AE monophthongs and diphthongs.
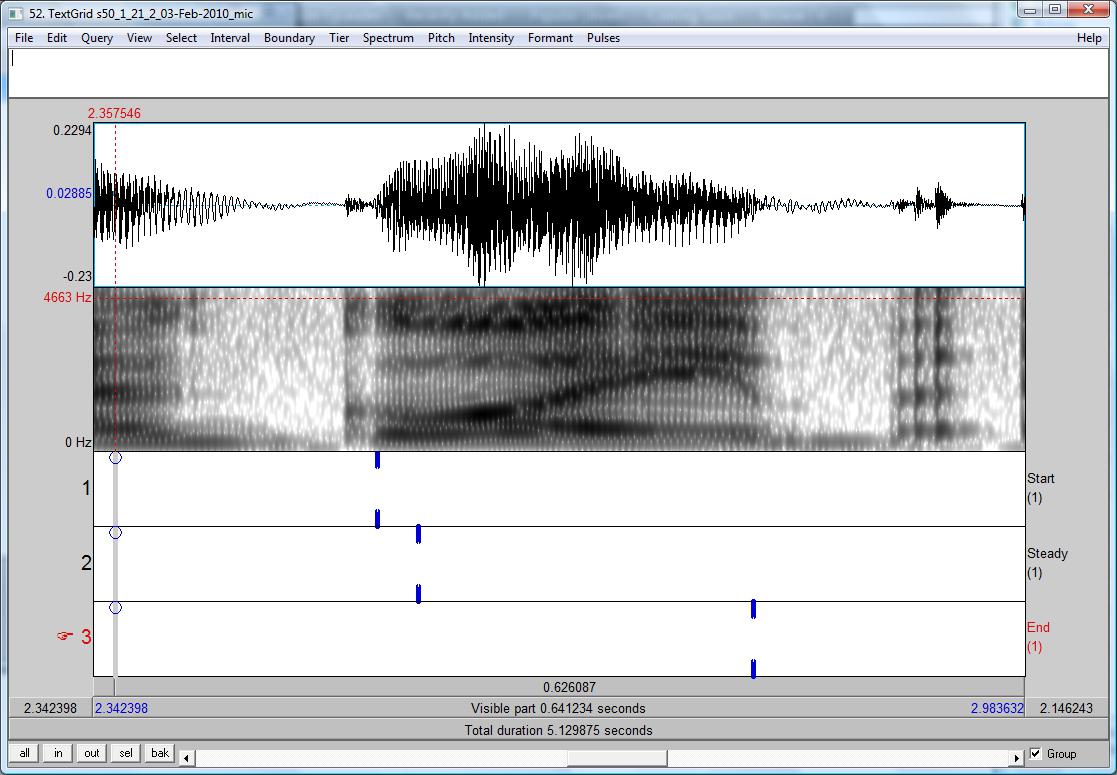
The target vowel in each utterance was hand-labeled to indicate the start, stop, and steady-state parts of the vowel. For diphthongs, the steady-state refers to the diphthong nucleus which occurs early in the vowel.
The height and age of each speaker is included in the corpus metadata.
Audio files are presented as single channel 16-bit flac compressed wav files with sample rates of 48kHz or 16kHz. Image files are bitmap image files and plain text is UTF-8.
Samples
Please view the following samples:
{kind=link}
Acknowledgment
This work was supported in part by National Science Foundation Grant No. 0905250.
Updates
None at this time.