ACE Time Normalization (TERN) 2004 English Evaluation Data V1.0
| Item Name: | ACE Time Normalization (TERN) 2004 English Evaluation Data V1.0 |
| Author(s): | Lisa Ferro, Laurie Gerber, Inderjeet Mani, Beth Sundheim, George Wilson |
| LDC Catalog No.: | LDC2010T18 |
| ISBN: | 1-58563-563-4 |
| ISLRN: | 719-248-950-383-6 |
| DOI: | https://doi.org/10.35111/7hfd-eg56 |
| Release Date: | October 15, 2010 |
| Member Year(s): | 2010 |
| DCMI Type(s): | Text |
| Data Source(s): | newswire, broadcast news |
| Project(s): | TIDES, TERN, TDT, ACE |
| Application(s): | summarization, question-answering, information extraction, automatic content extraction, temporal analysis |
| Language(s): | English |
| Language ID(s): | eng |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2010T18 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Ferro, Lisa, et al. ACE Time Normalization (TERN) 2004 English Evaluation Data V1.0 LDC2010T18. Web Download. Philadelphia: Linguistic Data Consortium, 2010. |
| Related Works: | View |
Introduction
ACE Time Normalization (TERN) 2004 English Evaluation Data V1.0, Linguistic Data Consortium (LDC) catalog number LDC2010T18 and isbn 1-58563-563-4, was developed by researchers at The MITRE Corporation. It contains the English evaluation data prepared for the 2004 Time Expression Recognition and Normalization (TERN) Evaluation, sponsored by the Automatic Content Extraction (ACE) program, specifically, English broadcast news and newswire data collected by LDC. The training data for this evaluation can be found in ACE Time Normalization (TERN) 2004 English Training Data v 1.0 LDC2005T07. The purpose of the TERN evaluation is to advance the state of the art in the automatic recognition and normalization of natural language temporal expressions. In most language contexts such expressions are indexical. For example, with "Monday," "last week," or "three months starting October 1," one must know the narrative reference time in order to pinpoint the time interval being conveyed by the expression. In addition, for data exchange purposes, it is essential that the identified interval be rendered according to an established standard, i.e., normalized. Accurate identification and normalization of temporal expressions are in turn essential for the temporal reasoning being demanded by advanced NLP applications such as question answering, information extraction and summarization.
Data
The data in this release is English broadcast transcripts and newswire material from TDT4 Multilingual Text and Annotations LDC2005T16. The annotation specifications for this corpus were developed under DARPA's Translingual Information Detection Extraction and Summarization (TIDES) program, with support from ACE. All files have been doubly-annotated by two separate annotators and then reconciled, using the TIDES 2003 Standard for the Annotation of Temporal Expressions (included in this release).
The table below illustrates the number of words and documents by genre:
| Words | Documents | |
| Broadcast news | 26418 | 127 |
| Newswire | 28196 | 65 |
| TOTAL | 54614 | 192 |
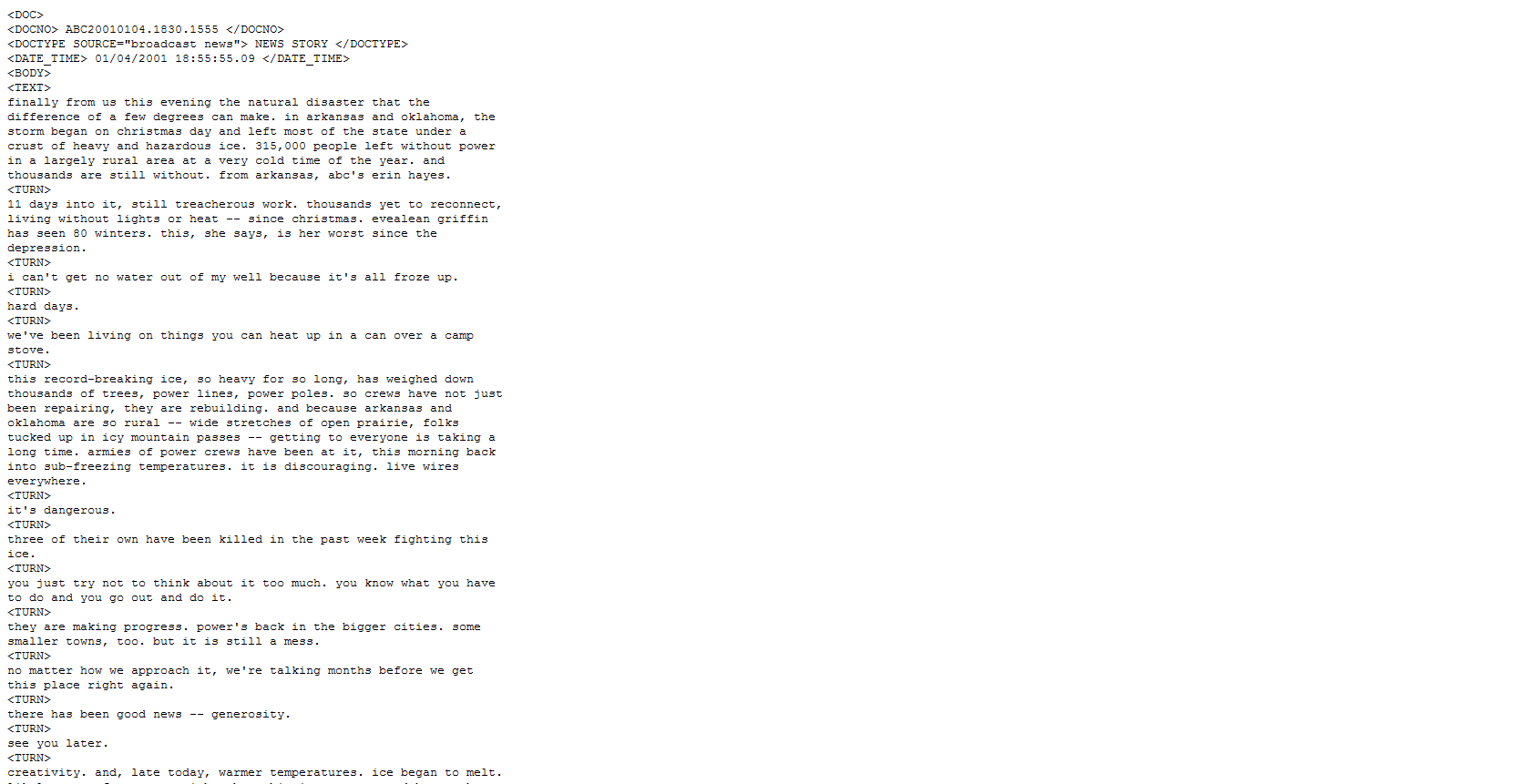
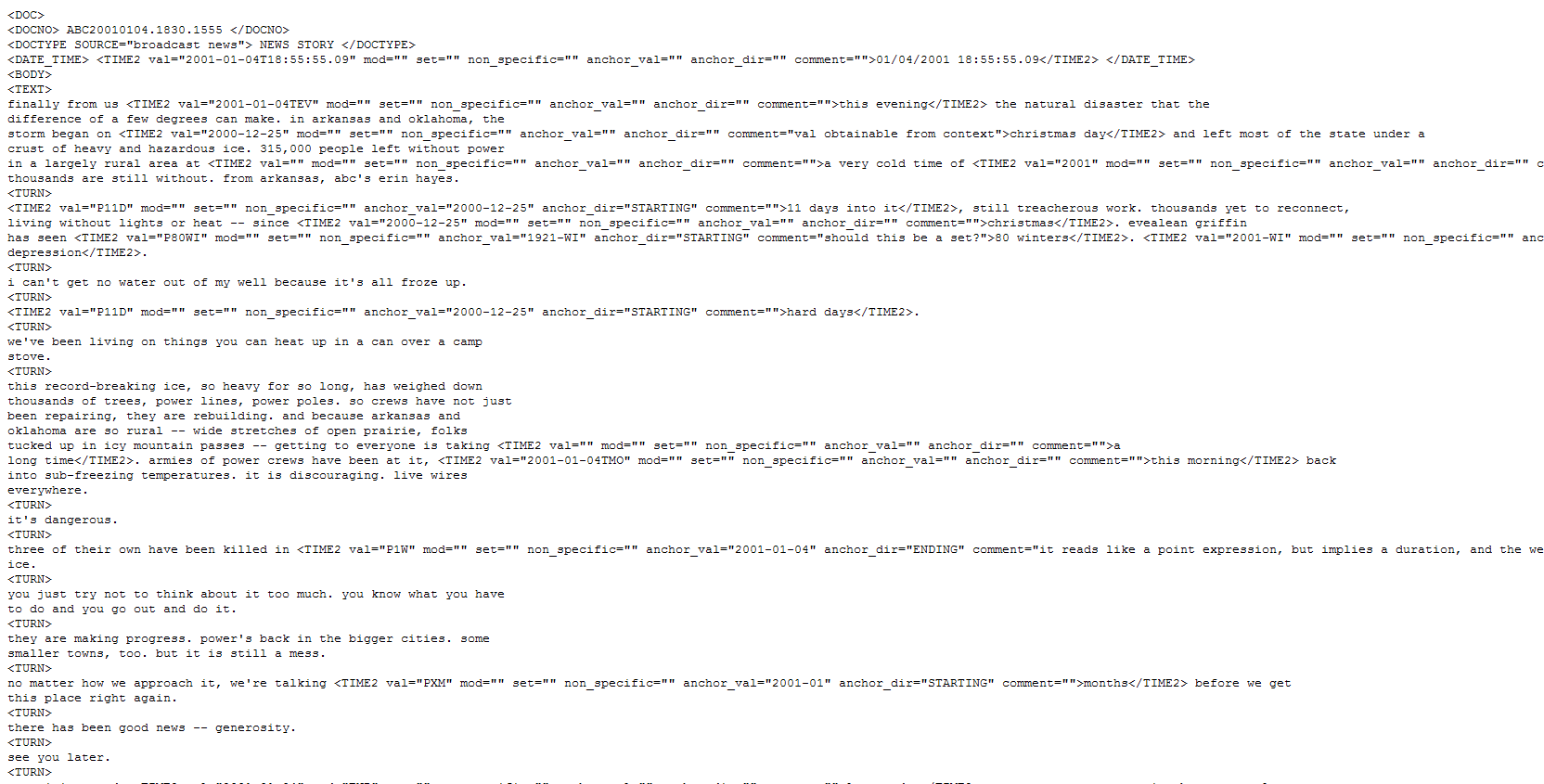
Samples
For an example of the data in this corpus, please review Sample 1 and Sample 2. Sample 1 depicts the source data files in sgml format and Sample 2 shows the annotated files, also in sgml format (*.tmx.sgml).
{kind=link}
{kind=link}
Updates
Additional information, updates, bug fixes may be available in the LDC catalog entry for this corpus at LDC2010T18.
Copyright
Portions © 2001 American Broadcasting Company, Cable News Network, LP, LLLP, National Broadcasting Company, Inc., New York Times, Public Radio International, The Associated Press, © 2002, 2003, 2005, 2010 Trustees of the University of PennsylvaniaThe World is a co-production of Public Radio International and the British Broadcasting Corporation and is produced at WGBH Boston.