American English Nickname Collection
| Item Name: | American English Nickname Collection |
| Author(s): | Vitor R. Carvalho, Yigit Kiran, Andrew Borthwick |
| LDC Catalog No.: | LDC2012T11 |
| ISBN: | 1-58563-619-3 |
| ISLRN: | 756-362-661-905-7 |
| DOI: | https://doi.org/10.35111/kjfh-jw12 |
| Release Date: | July 18, 2012 |
| Member Year(s): | 2012 |
| DCMI Type(s): | Text |
| Data Source(s): | varied |
| Application(s): | coreference resolution, entity extraction, language modeling, machine translation, named entity recognition, nominal expression generation, sociolinguistics |
| Language(s): | English |
| Language ID(s): | eng |
| License(s): |
American English Nickname Collection |
| Online Documentation: | LDC2012T11 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Carvalho, Vitor R., Yigit Kiran, and Andrew Borthwick. American English Nickname Collection LDC2012T11. Web Download. Philadelphia: Linguistic Data Consortium, 2012. |
Introduction
American English Nickname Collection was developed by Intelius, Inc. and is a compilation of American English nicknames to given name mappings based on information in US government records, public web profiles and financial and property reports. This corpus is intended as a tool for the quantitative study of nickname usage in the United States such as in demographic and sociological studies. It has multiple potential human language technology applications as well, including entity extraction, coreference resolution, people search, language modeling and machine translation.
Data
The American English Nickname Collection contains 331,237 distinct mappings encompassing millions of names. The data was collected and processed through a record linkage pipeline. The steps in the pipeline were (1) data cleaning, (2) blocking, (3) pair-wise linkage and (4) clustering. In the cleaning step, material was categorized, processed to remove junk and spam records and normalized to an approximately common representation. The blocking process utitlized an algorithm to group records by shared properties for determining which record pairs should be examined by the pairwise linker as potential duplicates. The linkage step assigned a score to record pairs using a supervised pairwise-based machine learning model. The clustering step combined record pairs into connected components and further partitioned each connected component to remove inconsistent pairwise links. The result is that input records were partitioned into disjoint sets called profiles, where each profile corresponded to a single person.
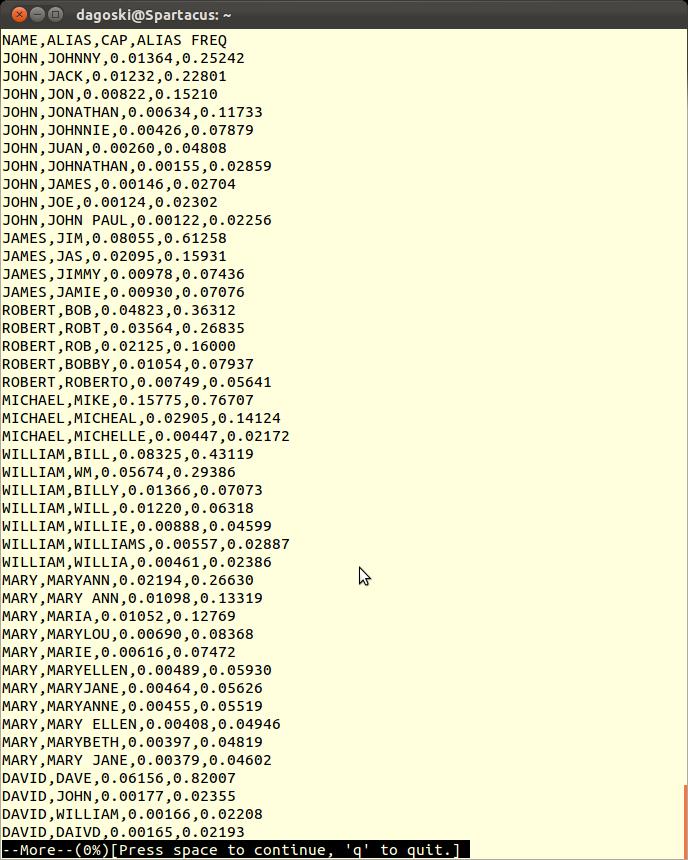
The material is presented in the form of a comma delimited text file. Each line contains a first name, a nickname or alias, its conditional probability and its frequency. The conditional probability for each nickname is derived from the base data using an algorithim which calculates both the probability for which any alias refers to a given name and a threshold below which the mapping is most likely an error. This threshold eliminates typographic errors and other noise from the data.
Samples
Please view this image sample.
{kind=link}
Portions © 2012 Intelius, Inc., © 2012 Trustees of the University of Pennsylvania