OntoNotes Release 5.0
| Item Name: | OntoNotes Release 5.0 |
| Author(s): | Ralph Weischedel, Martha Palmer, Mitchell Marcus, Eduard Hovy, Sameer Pradhan, Lance Ramshaw, Nianwen Xue, Ann Taylor, Jeff Kaufman, Michelle Franchini, Mohammed El-Bachouti, Robert Belvin, Ann Houston |
| LDC Catalog No.: | LDC2013T19 |
| ISBN: | 1-58563-659-2 |
| ISLRN: | 151-738-649-048-2 |
| DOI: | https://doi.org/10.35111/xmhb-2b84 |
| Release Date: | October 16, 2013 |
| Member Year(s): | 2013 |
| DCMI Type(s): | Text |
| Data Source(s): | telephone conversations, newswire, newsgroups, broadcast news, broadcast conversation, weblogs, religious texts |
| Project(s): | GALE |
| Application(s): | information extraction, information retrieval |
| Language(s): | English, Mandarin Chinese, Arabic, Chinese |
| Language ID(s): | eng, cmn, ara, zho |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2013T19 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Weischedel, Ralph, et al. OntoNotes Release 5.0 LDC2013T19. Web Download. Philadelphia: Linguistic Data Consortium, 2013. |
| Related Works: | View |
Introduction
OntoNotes Release 5.0 is the final release of the OntoNotes project, a collaborative effort between BBN Technologies, the University of Colorado, the University of Pennsylvania and the University of Southern Californias Information Sciences Institute. The goal of the project was to annotate a large corpus comprising various genres of text (news, conversational telephone speech, weblogs, usenet newsgroups, broadcast, talk shows) in three languages (English, Chinese, and Arabic) with structural information (syntax and predicate argument structure) and shallow semantics (word sense linked to an ontology and coreference).
OntoNotes Release 5.0 contains the content of earlier releases -- OntoNotes Release 1.0 LDC2007T21, OntoNotes Release 2.0 LDC2008T04, OntoNotes Release 3.0 LDC2009T24 and OntoNotes Release 4.0 LDC2011T03 -- and adds source data from and/or additional annotations for, newswire (News), broadcast news (BN), broadcast conversation (BC), telephone conversation (Tele) and web data (Web) in English and Chinese and newswire data in Arabic. Also contained is English pivot text (Old Testament and New Testament text). This cumulative publication consists of 2.9 million words with counts shown in the table below.
| Arabic | English | Chinese | |
| News | 300k | 625k | 250k |
| BN | n/a | 200k | 250k |
| BC | n/a | 200k | 150k |
| Web | n/a | 300k | 150k |
| Tele | n/a | 120k | 100k |
| Pivot | n/a | n/a | 300 |
The OntoNotes project built on two time-tested resources, following the Penn Treebank for syntax and the Penn PropBank for predicate-argument structure. Its semantic representation includes word sense disambiguation for nouns and verbs, with some word senses connected to an ontology, and coreference.
Data
Documents describing the annotation guidelines and the routines for deriving various views of the data from the database are included in the documentation directory of this release. The annotation is provided both in separate text files for each annotation layer (Treebank, PropBank, word sense, etc.) and in the form of an integrated relational database (ontonotes-v5.0.sql.gz) with a Python API to provide convenient cross-layer access.
It is a known issue that this release contains some non-validating XML files. The included tools, however, use a non-validating XML parser to parse the .xml files and load the appropriate values.
Tools
This release includes OntoNotes DB Tool v0.999 beta, the tool used to assemble the database from the original annotation files. It can be found in the directory tools/ontonotes-db-tool-v0.999b. This tool can be used to derive various views of the data from the database, and it provides an API that can implement new queries or views. Licensing information for the OntoNotes DB Tool package is included in its source directory.
Samples
Please view these samples:
{kind=link}
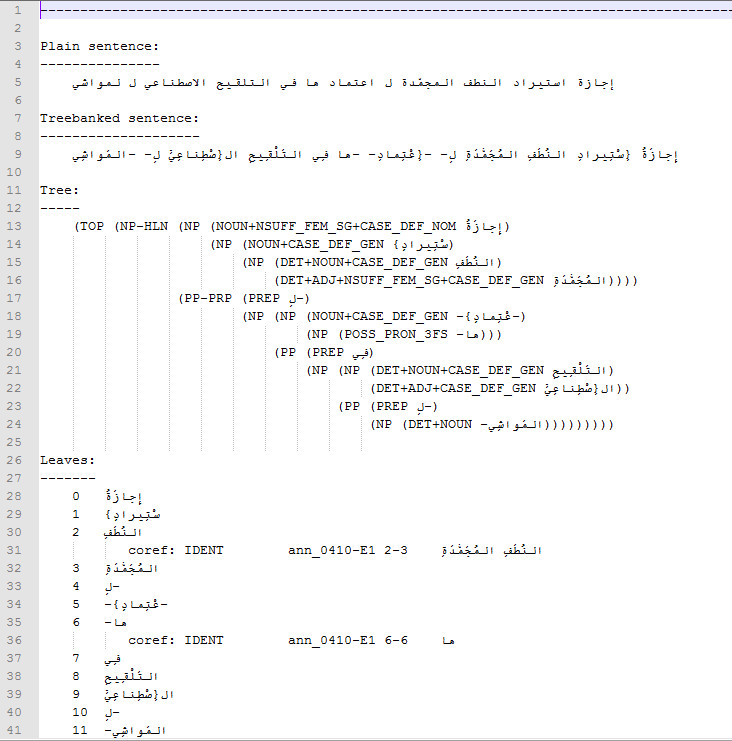{kind=link}
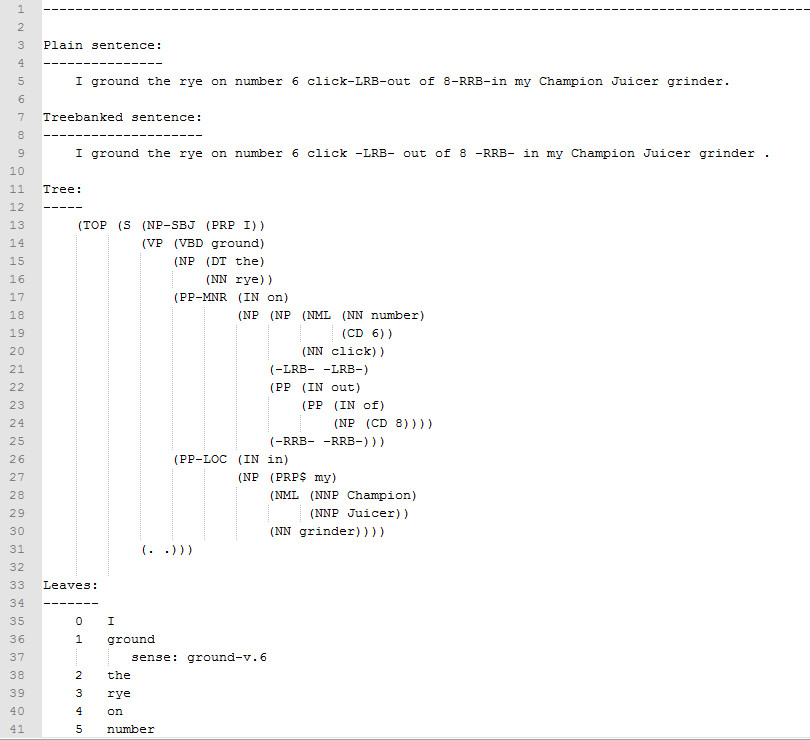{kind=link}
Updates
Additional documentation was added on December 11, 2014 and is included in downloads after that date.
Acknowledgment
This work is supported in part by the Defense Advanced Research Projects Agency, GALE Program Grant No. HR0011-06-1-003. The content of this publication does not necessarily reflect the position or policy of the Government, and no official endorsement should be inferred.