TS Wikipedia
| Item Name: | TS Wikipedia |
| Author(s): | Taner Sezer, Türker Sezer |
| LDC Catalog No.: | LDC2015T15 |
| ISBN: | 1-58563-723-8 |
| DOI: | https://doi.org/10.35111/mem6-4951 |
| Release Date: | July 15, 2015 |
| Member Year(s): | 2015 |
| DCMI Type(s): | Text |
| Data Source(s): | web collection |
| Application(s): | part of speech tagging, information extraction, morphology |
| Language(s): | Turkish |
| Language ID(s): | tur |
| License(s): |
Creative Commons-Attribution-Share-Alike 3.0 (NFP, Non-Member)
LDC For-Profit Membership Agreement |
| Online Documentation: | LDC2015T15 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Sezer, Taner, and Türker Sezer. TS Wikipedia LDC2015T15. Web Download. Philadelphia: Linguistic Data Consortium, 2015. |
Introduction
TS Wikipedia is a collection of approximately 1.6 million processed Turkish Wikipedia pages. The data is tokenized and includes part-of-speech tags, morphological analysis, lemmas, bi-grams and tri-grams.
Data
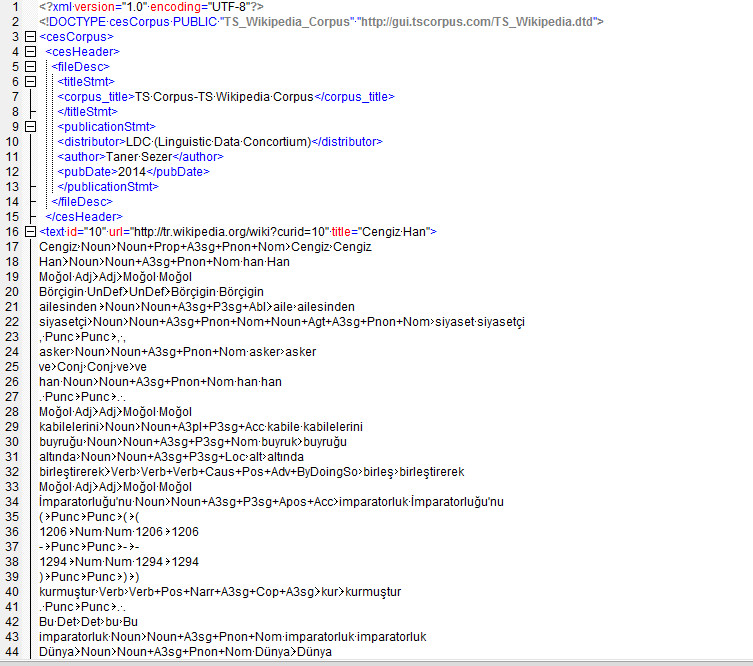
The data is in a word-per-line format with five tab-separated columns: token, part-of-speech tag, morphological analysis, lemma and corrected token spelling if needed. All data is presented in UTF-8 XML files and was selected and filtered to reduce non-Turkish characters, mathematical formulas and non-Turkish entries.
Samples
Please view this sample.
{kind=link}
Updates
None at this time.