


This section describes the visual representation of the directory structure contained in the CD-ROM up to its second, or third tier (see Table 3.1). Any references made regarding the content of the CD-ROM that resides deeper within the tree structure notes the full path to the file.
Table 3.1. CAC 2.0 CD-ROM – Directory structure
index.html | # CAC 2.0 Guide in Czech (html) | |||
index-en.html | # CAC 2.0 Guide in English (html) | |||
Install-on-Linux.pl | # Install script for Linux (English) | |||
Install-on-Windows.exe | # Installation program for MS Windows (English) | |||
Instaluj-na-Linuxu.pl | # Installation script for Linux (Czech) | |||
Instaluj-na-Windows.exe | # Installation program for MS Windows (Czech) | |||
bonus-tracks/ | # Bonus material | |||
| # Electronic exercise book of Czech language | |||
data/ | # Data component | |||
| # CAC 2.0 in CSTS format (files [ans][0-9][0-9][sw].csts) | |||
| # CAC 2.0 in PML format (files [ans][0-9][0-9][sw].[amw]) | |||
| # PML schemes and dtd of CSTS format | |||
doc | # Documentation | |||
| # CAC 2.0 Guide in Czech and English (pdf) | |||
tools/ | # Tools | |||
| # Corpus manager | |||
| # Java Runtime Environment 6 Update 3 for Linux and MS Windows | |||
| # Editor of morphological annotations | |||
| # Editor of syntactical annotations, including the TrEdVoice module for voice control | |||
| # Corpus viewing and searching tool | |||
| # Tools for the automatic processing of Czech texts | |||
| # Script running the tokenisation and/or morphological analysis and/or tagging and/or parsing | |||
| ||||
tutorials/ | # Tutorials for the data and the tools |
This section describes the inner representation of the files itself, the rules used to name the files, and the organisation of the CAC 2.0 corpus into files.
We used the Prague Markup Language (PML) as the main data format. The PML is a generic XML-based [31] data format designed for the representation of the rich linguistic annotation of text. Each of the annotation layers is represented by a single PML instance. The PML was developed in concurrence with the annotation of the PDT 2.0.
A secondary data format used in the CAC 2.0 is a format named CSTS. This is an SGML-based [20] format used in the PDT 1.0 annotation and also in the Czech National Corpus [14]. The reason why we use a secondary format for the CAC 2.0 is its more efficient human readability, the ease of its processing by simple tools and also the fact that some of the tools developed for the CAC 2.0 are only able to work with the CSTS format. A conversion tool for these two formats is also available.
In the following section you will find a summary of the main characteristics of the PML format; detailed information has been published in a technical report (Pajas, Štěpánek, 2005). The next section contains a summary of the main characteristics of the CSTS format. For more detailed information see the PDT 2.0 documentation [13].
The layers of annotation can overlap or be linked together in the PML as well as with other data sources in a consistent way. Each layer of annotation is described in a PML schema file, which can be seen as the formalisation of an abstract annotation scheme for the particular layer of annotation. The PML schema file describes which elements occur in that layer, how they are nested and structured, what the attribute types are for the corresponding values, and what role they play in the annotation scheme (this PML-role information can also be used by applications to determine an adequate way to present a PML instance to the user). New schemata can be automatically generated out of the PML scheme, e.g. Relax NG [19]. This means that data consistence can be checked by common XML tools. Both versions of the schemata are available in the directory data/schemas/. An example of the w-layer part of the PML schema of the CAC can be found in Table 3.2 (data/schemas/wdata_schema.xml). In the illustrated example, the paragraph (type para, the whole document in the case of the CAC 2.0) consists of an array of w-node.type elements. This type is closely defined as a structure also containing obligatory elements: id (unambiguous identifier with the role of #ID) and token (word unit).
Table 3.2. The PML schema of the w-layer in the CAC 2.0
| <type name="w-para.type"> <sequence> <element name="w" type="w-node.type"/> ... </sequence> </type> <type name="w-node.type"> <structure name="w-node"> <member as_attribute="1" name="id" role="#ID" required="1"> <cdata format="ID"/></member> <member name="token" required="1"> <cdata format="any"/> </member> <member name="no_space_after" type="bool.type"/> </structure> </type> ... |
Every PML instance begins with a header referring to the PML schema. The header contains references to all external sources that are being referred to from this instance, together with some additional information necessary for the correct link resolving. The rest of the instance is dedicated to the annotation itself. Table 3.3 provides an example of the head of an m-layer instance (n01w.m) with a reference to a PML schema (mdata_schema.xml) and the appropriate instance within the w-layer (n01w.w).
Table 3.3. Part of the header of the m-layer instance n01w.m
| <head> <schema href="mdata_schema.xml" /> <references> <reffile id="w" href="n01w.w" name="wdata" /> </references> </head> ... |
Table 3.4 similarly shows the referential part of the header of the instance of the a-layer (n01w.a), referring to the PML-schema of that instance ( adata_schema.xml) and the corresponding m-layer instance (n01w.m) and w-layer instance (n01w.w).
Table 3.4. Part of the header of the a-layer instance n01w.a
| <head> <schema href="adata_schema.xml" /> <references> <reffile id="m" href="n01w.m" name="mdata" /> <reffile id="w" href="n01w.w" name="wdata" /> </references> </head> ... |
The annotation is expressed using XML elements and attributes named and used according to their corresponding PML schema. Table 3.5 illustrates an example of the morphological annotation of a part of the sentence Váš boj je i naším bojem (Lit.: Your fight is our fight too). The opening tag of the element s contains an identifier of the whole sentence followed by the opening tag of the element m, which contains identifiers to the annotation corresponding to the token of the w-layer that are being referred to from the element w.rf. Other elements contain the form (form), morphological tag (tag) and src.rf provides the source of the annotation, in this case a manual annotation.
Table 3.5. An example of sentence m-layer annotation in the PML format
| <s id="m-n01w-s14"> <m id="m-n01w-s14W1"> <src.rf>manual</src.rf> <w.rf>w#w-n01w-s14W1</w.rf> <form>Váš</form> <lemma>tvůj_^(přivlast.)</lemma> <tag>PSYS1-P2-------</tag> </m> <m id="m-n01w-s14W2"> <src.rf>manual</src.rf> <w.rf>w#w-n01w-s14W2</w.rf> <form>boj</form> <lemma>boj</lemma> <tag>NNIS1-----A----</tag> </m> <m id="m-n01w-s14W3"> <src.rf>manual</src.rf> <w.rf>w#w-n01w-s14W3</w.rf> <form>je</form> <lemma>být</lemma> <tag>VB-S---3P-AA---</tag> </m> ... <m id="m-n01w-s14W7"> <src.rf>manual</src.rf> <form_change>insert</form_change> <form>.</form> <lemma>.</lemma> <tag>Z:-------------</tag> </m> </s> |
Table 3.6 shows an example of the analytic annotation of a sentence Váš boj je i naším bojem. (Lit.: Your fight is our fight too.) The less important elements have been left out to make the example more transparent. The dependency structure of the sentence is represented by structured nested elements. Daughter nodes are enveloped by the element children. Furthermore, each node is enveloped in the element LM with the identifier of this node as an attribute; lists of single nodes are the only exception, as this element can be omitted for them. The identifier of the node becomes an attribute of the element children. The element m.rf links to the corresponding element of the lower layer containing the particular word form. The element afun contains the analytical function of the node. The element ord contains the sequential number of the node in the tree in left-to-right order. This number is equal to the word order in the sentence.
Table 3.6. An example of sentence a-layer annotation in the PML format
| <LM id="a-n01w-s14"> <s.rf>m#m-n01w-s14</s.rf> <afun>AuxS</afun> <ord>0</ord> <children> <LM id="a-n01w-s14W3"> <afun>Pred</afun> <m.rf>m#m-n01w-s14W3</m.rf> <ord>3</ord> <children> <LM id="a-n01w-s14W2"> <afun>Sb</afun> <m.rf>m#m-n01w-s14W2</m.rf> <ord>2</ord> <children id="a-n01w-s14W1"> <afun>Atr</afun> <m.rf>m#m-n01w-s14W1</m.rf> <ord>1</ord> </children> </LM> <LM id="a-n01w-s14W6"> <afun>Pnom</afun> <m.rf>m#m-n01w-s14W6</m.rf> <ord>6</ord> <children id="a-n01w-s14W5"> <afun>Atr</afun> <m.rf>m#m-n01w-s14W5</m.rf> <ord>5</ord> <children id="a-n01w-s14W4"> <afun>AuxZ</afun> <m.rf>m#m-n01w-s14W4</m.rf> <ord>4</ord> </children> </children> </LM> </children> </LM> <LM id="a-n01w-s14W7"> <afun>AuxK</afun> <m.rf>m#m-n01w-s14W7</m.rf> <ord>7</ord> </LM> </children> </LM> |
XML elements of a PML instance occupy a dedicated namespace: http://ufal.mff.cuni.cz/pdt/pml/ (this is not a real link, it is just a name of the namespace). The PML format offers unified representations for the most common annotation constructs, such as attribute-value structures, lists of alternative values of a certain type (either atomic or further structured), references within a PML instance, links among various PML instances (used in the CAC 2.0 to create links across layers), and links to other external XML-based resources.
A single file in CSTS format can contain all layers of annotation.
A CSTS format file opens with a (facultative) header (element h) followed by at least one doc element. The element doc consists of a header (element a) and contents (element c). The element c is then formed by a sequence of paragraphs (element p) and sentences of those paragraphs (element s).
Each word token of the sentence is placed on a separate line in the file (element f or d for punctuation). The line continues with the annotations of this word token on all layers. The element l is filled with the lemma, the element t contains its morphological tag. The element A is filled with the analytical function of the word token. The unique identifier of the word token in the sentence is stored in the element r. The element g contains a link to the governing node of the word in the form of an identifier of that governing node.
See Table 3.7 for an example of the complete annotation of the sentence Váš boj je i naším bojem. (Lit.: Your fight is our fight too.) in CSTS format.
Table 3.7. An example of sentence annotation in CSTS format
| <s id=n01w-s14> <f id=n01w-s14W1>Váš<l>tvůj_^(přivlast.)<t>PSYS1-P2------- <r>1<g>2<A>Atr <f id=n01w-s14W2>boj<l>boj<t>NNIS1-----A----<r>2<g>3<A>Sb <f id=n01w-s14W3>je<l>být<t>VB-S---3P-AA---<r>3<g>0<A>Pred <f id=n01w-s14W4>i<l>i<t>J^-------------<r>4<g>5<A>AuxZ <f id=n01w-s14W5>naším<l>můj_^(přivlast.)<t>PSZS7-P1------- <r>5<g>6<A>Atr <f id=n01w-s14W6>bojem<l>boj<t>NNIS7-----A----<r>6<g>3<A>Pnom <D> <d id=n01w-s14W7>.<l>.<t>Z:-------------<r>7<g>0<A>AuxK |
The DTD file for CSTS format can be found in the directory data/schemas/. For more detailed information on this format see the PDT 2.0 documentation [13].
Directories tools/tool_chain/csts2pml/ and tools/tool_chain/pml2csts/ provide conversion scripts for the two formats.
Each data file used in the CAC 2.0 relates to one annotated document. The base of the file name contains a single letter that classifies the subject of the text contained in the file. Namely n indicates newspaper articles, s marks scientific texts, and a denotes administrative texts. Next, the file name specifies a two-digit ordinal number of the document within a group of documents of the same style. Following this two-digit number, a letter indicates if the text is derived from a written text (letter w) or if it is a transcript of spoken language (letter s). The file names of the documents are included as the identifiers of sentences and elements in these sentences, e.g. <m id="m-n01w-s1W1"> in table 3.5. See Appendix A for file names of each document.
Example: Instances noted according to template a[0-9][0-9]s* contain transcripts of the spoken language in an administrative style.
In PML format, the file extension embodies the layer of the document’s annotation. The extension of w-layer files is .w, .m denotes m-layer and .a denotes a-layer. Then they will be referred to as w-files, m-files and a-files. Each a-file exactly corresponds to one m-file and one w-file. Each a-file contains links to the corresponding m-file and w-file, and each m-file contains links to the corresponding w-file (see above). Due to this dependency, it is critical that files not be renamed. There are no links from w-files to m-files (or a-files), as well as there are no links from m-files into a-files.
In CSTS format, there is the “csts” extension for all the files.
Example: The code s17w.a defines a PML instance containing the a-layer annotations of a document written in a scientific style. The file links to s17w.m and s17w.w files, file s17w.m links to s17w.w file. The code s17w.csts defines a CSTS file containing all layers (w-layer, m-layer, a-layer) annotation of a document written in a scientific style.
The CAC 2.0 is composed of 180 manually annotated documents containing 31,707 sentences and 652,131 tokens as calculated from the m-files. Tokens without punctuation total 570,760 and tokens without punctuation and digit tokens reach 565,910. Table 3.8 states the sizes of the individual parts of the data according to its style and form.
Table 3.8. Size of the CAC 2.0 parts according to style and form
| Style | Form | Number of docs | Number of sentences | Number of word tokens | Number of word tokens w/o punctuation | Number of word tokens w/o punctuation and digit tokens |
|---|---|---|---|---|---|---|
| Journalism | Written | 52 | 10 234 | 189 435 | 165 469 | 163 693 |
| Journalism | Transcription | 8 | 1433 | 28 737 | 24 864 | 24 859 |
| Scientific | Written | 68 | 11 113 | 245 174 | 216 280 | 214 127 |
| Scientific | Transcription | 32 | 4576 | 115 853 | 100 281 | 100 272 |
| Administrative | Written | 16 | 3362 | 58 697 | 51 431 | 50 524 |
| Administrative | Transcription | 4 | 989 | 14 235 | 12 435 | 12 435 |
| Total | Written | 136 | 24 709 | 493 306 | 433 180 | 428 344 |
| Total | Transcription | 44 | 6998 | 158 825 | 137 580 | 137 566 |
| Total | Written and transcription | 180 | 31 707 | 652 131 | 570 760 | 565 910 |
Table 3.9 contains separate quantitative data for the characters “#” and “?” that were manually inserted into the CAC to replace missing words and numbers written as digits.
Table 3.9. Quantitative characteristics of the CAC 2.0 – replacement characters “#” and “?”
| Style | Form | Number of “#” characters (in a specified number of sentences) | Number of “?” (in a specified number of sentences) | Number of “#” or “?” (in a specified number of sentences) | Number of sentences not containing replacement symbols |
|---|---|---|---|---|---|
| Journalism | Written | 1,776 (1,187) | 925 (680) | 2,701 (1,563) | 8,671 |
| Journalism | Transcription | 5 (5) | 25 (25) | 30 (30) | 1,403 |
| Scientific | Written | 2,153 (1,224) | 2,230 (1,418) | 4,383 (2,031) | 9,082 |
| Scientific | Transcription | 9 (9) | 1,31 (108) | 140 (113) | 4,463 |
| Administrative | Written | 907 (616) | 635 (476) | 1,542 (919) | 2,443 |
| Administrative | Transcription | 0 (0) | 16 (15) | 16 (15) | 974 |
Every experiment conducted on the CAC 2.0 data made public should contain information about the data that was used to obtain the derived results.
The Annotation of the CAC 2.0 is divided into three layers: the w-layer (word layer), m-layer (morphological layer) and a-layer (analytical layer). Each of these layers includes its own PML schema located in the directory structure (data/schemas/ files wdata_schema.xml, mdata_schema.xml, adata_schema.xml). The directory structure data/pml/ is composed of a total of 496 files: 180 w-files, 180 m-files and 136 a-files. Transcriptions have not been annotated on the a-layer. It is impossible to apply the guidelines for the syntactical annotation of the written texts to the annotation of the spoken texts.
data/csts/ contains 180 files of this same data in CSTS format: 136 consist of morphological and syntactical annotations
and 44 only morphological annotations. With regards to target to integrate the CAC into the PDT, we present Table 3.10 that compares the basics of both corpora. We only mention the characteristics common to both corpora. The CAC 2.0 will be integrated into the PDT when the next version of the PDT is published.
Table 3.10. A comparison of the CAC 2.0 and the PDT 2.0
| Characteristics | PDT 2.0 | CAC 2.0 | |||
|---|---|---|---|---|---|
| Number of words (thousands) | Number of sentences (thousands) | Number of words (thousands) | Number of sentences (thousands) | ||
| Morphological annotation | 2,000 | 116 | 652 | 32 | |
| Analytical annotation | 1,500 | 88 | 493 | 25 | |
| Written form | 2,000 | 116 | 493 | 25 | |
| Transcriptions | -- | -- | 159 | 7 | |
| Journalistic style | 1,620 | 94 | 218 | 12 | |
| Administrative style | -- | -- | 73 | 4 | |
| Scientific style | 380 | 22 | 361 | 16 | |
We provide the whole range of tools for data annotations, annotation corrections, searching within the annotated data and automatic data processing. Considering the fact that the CAC 2.0 is annotated on the m-layer and a-layer, we provide the tools for working with the CAC (and other) data on these two layers. Table 3.11 helps the user to orient himself to the tools contained on this CD-ROM. Each tool is described by its main features and its appointed kind of use. The following sections describes the tools in more detail.
Table 3.11. Tools – outline
| Tool | Description | Purpose |
|---|---|---|
| Bonito | Corpus manager |
|
| LAW | Morphological annotations editor |
|
| TrEd | Syntactical annotations editor |
|
| Netgraph | Corpus viewer |
|
| tool_chain | Automatic procedure processing Czech texts |
|
The graphic tool Bonito [32] simplifies tasks commonly associated with language corpora, especially searching within them and calculating basic statistics on the search results. Bonito is a graphical interface to the corpus manager Manatee, which conducts various operations on corpus data. A detailed documentation for the Bonito tool is included in the application itself and can be launched from the main Help menu.
Figure 3.1 illustrates the Bonito main screen. The command of the tool is demonstrated in the following examples.
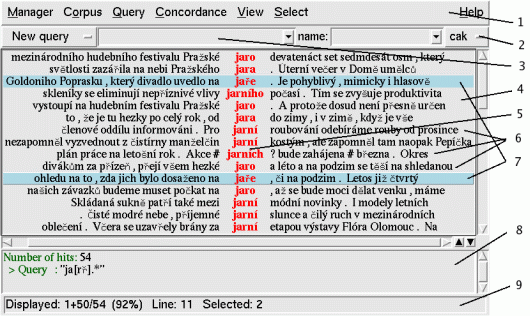
Figure 3.1 description
1 Main menu
2 Corpus selection button
3 Query line
4 Main window displaying query results
5 Column of the query results
6 Concordance lines
7 Selected concordance lines
8 Window for displaying query history and broader context
9 Status line
Bonito makes it possible to run the Czech morphological analyser directly through the menu Manager | Morphology. This command opens a new window; the user can keep this window open while working with the corpus tool. It can be used to run morphological analysis or synthesis (generating). The morphological analysis of a given word lists all possible lemmas and tags corresponding to the entered word form. In case a synthesis is selected, the tool generates all possible word forms that can be generated from the given lemma and the corresponding tags. See Figure 3.2.
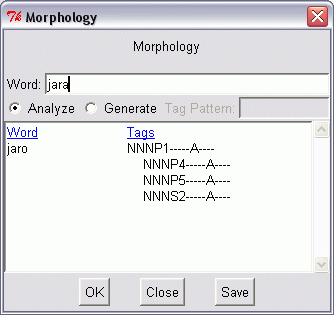
The tutorial contains more detailed information how to master Bonito.
The Lexical Annotation Workbench (LAW, [33]) is an integrated environment for morphological annotation. It supports simple morphological annotation (assigning a lemma and tag to a word), the comparison of different annotations of the same text, and searching for a particular word, tag etc. The workbench runs on all operating systems supporting Java, including Windows and Linux. It is an open system extensible via external modules – e.g. for different data views, import/export filters, assistants. The LAW editor supports PML [15], CSTS [13] and TNT [38] formats.
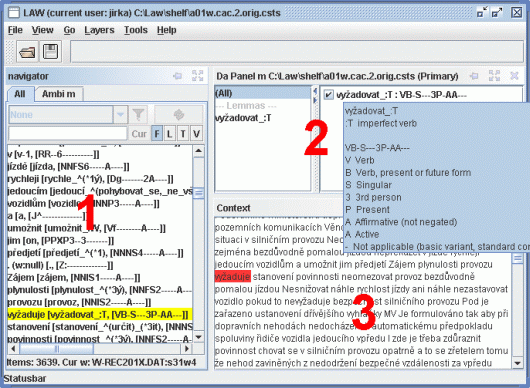
Navigator – For navigating through words of the document that have been filtered by different criteria and the selection of words for disambiguation.
Da Panels – For displaying and disambiguating morphological information (lemmas, tags) of a word. The panel consists of two windows – a grouping list and a list of items. The latter displays all the lemma-tag pairs associated with the current word (on the particular m-layer). The former makes it possible to restrict the items to a particular group, e.g., items with a particular lemma, detailed pos or gender. One of the panels is always defined as primary – certain actions apply to that panel only (e.g. Ctrl-T activates the list of lemmas and tags in the main panel).
Context Windows – Contain various context information, e.g. plain text of the document, syntactic structures, etc.
Open the desired m-file:
File | Open(Ctrl-O). The associated w-file opens automatically.Switch to the ambi-list (Ambi+ name of m-file) in the Navigator that is displaying the ambiguous words (words with more than one result of the morphological analysis) and select the first word.
-
Press
Enter. The cursor moves to the primary Da Panel. Select the correct lemma and tag and pressEnteragain. The cursor will move to the next ambiguous word.In case you make a mistake, switch to the list of all entries in the Navigator (All), find the word you want to review and select it. The Da Panel will display the corresponding annotation. You can now select the correct lemma and tag and then switch back to the Ambi X list.
Save the annotations:
File | Save(Ctrl-S).
The Tree Editor (TrEd, [37]) is a fully integrated environment primarily designed for the syntactical annotations of tree structures assigned to sentences. The editor can also be used for data viewing and searching with the help of several kinds of search functions.
The TrEd supports the PML and CSTS formats of input and output. More details on these formats can be found in 3.2.1. The TrEd system is highly modular, which means support for other formats can be easily plugged in.
The TrEd offers various possibilities of custom settings. User-defined macros in the Perl language can extend its functionality. Macros are called upon from menus or through the assigned hotkeys.
Users oriented with programming will certainly be able utilise the TrEd version without graphical user interface – called “btred” – for batch data processing (the Batch-mode Tree Editor). The NTrEd tool is another add-on to the editor. It brings with it the possibility to parallelise the “btred” processes and to distribute them on more computing machines.
To open the files in the TrEd use the menu command File | Open. Choose a file with the extension *.a or *.csts. The file opens in the TrEd and the first sentence of the file displays on the screen.
Figure 3.4 shows a typical TrEd screen. The sentence Problémy motivace jsou tak staré jako lidstvo. (E.: The motivational problems are as old as the human race.) Please find the explanatory notes below.
1. A window shows the tree representing the syntactical annotation of the sentence.
2. The represented sentence.
3. Status line: The status line shows various information on the selected word (the highlighted node, in our case Problémy). In our example the ID number of the node, its lemma and tag are displayed.
4. Current context. The environment for working with the annotations is called the context. There is a context which only allows the user to view the annotations (e.g. the PML_A_View context serves for viewing the syntactical annotations), another context might enable changing the annotations (e.g. the PML_A_Edit context allows for editing the annotations). To change the context, click on the current context name and choose another context from the pop-up list.
5. Current display style. The display style can be changed in the same way as the context.
6. Editing the display style.
7. Viewing the list of all sentences in the open file.
8. Buttons for opening, saving and re-opening a file.
9. Buttons for moving to the previous or following tree in the open file and for window management.
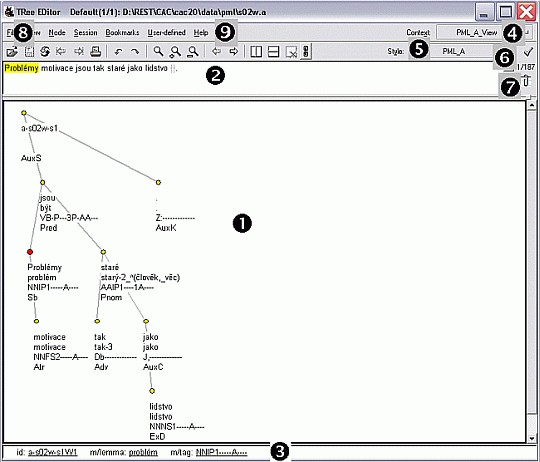
The CAC 2.0 files open in the PML_A_View context by default. In this context the user can view the trees and the editing is disabled. In case you wish to edit the trees, switch to the PML_A_Edit context. Both contexts offer only a single display style – PML_A. To view the list of all defined macros and the hotkeys assigned to them for any currently used context choose View | List of Named Macros from the menu.
Netgraph [35] is a client-server application for searching through and viewing the CAC 2.0. Several users can view the corpus online at the same time. The Netgraph has been designed for simple and intuitive searching while maintaining the high search power of the query language (Mírovský, 2008).
A query in Netgraph is formulated as a node or tree with defined characteristics that should match the required trees in the corpus. Therefore, searching the corpus means searching for sentences (annotated into the form of trees) containing the given node or tree. The user’s queries can range from the very simple (e.g. searching for all trees in the corpus containing a desired word) to the more advanced queries (e.g. searching for all sentences containing a verb with a dependent object, where the object is not in dative, and there is at least one dependent adverbial, etc.). So called meta attributes enable searching for even more complex structures.
The Netgraph tool offers a user friendly graphical interface for query formulation. See Figure 3.5 as an example. This simple query searches for all the trees containing a node marked as the predicate that has at least two dependent nodes marked as subject and object. The order of these dependent nodes is not specified in the query.
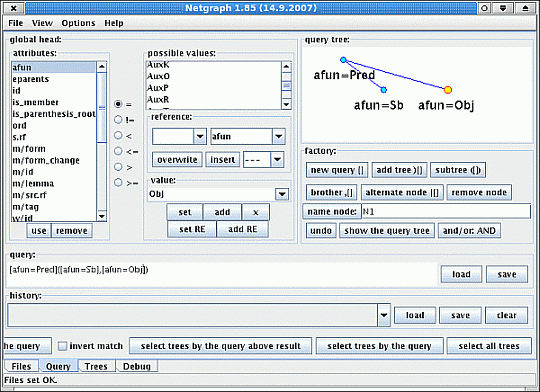
The tree in Figure 3.6 could be one of the results the server returns.
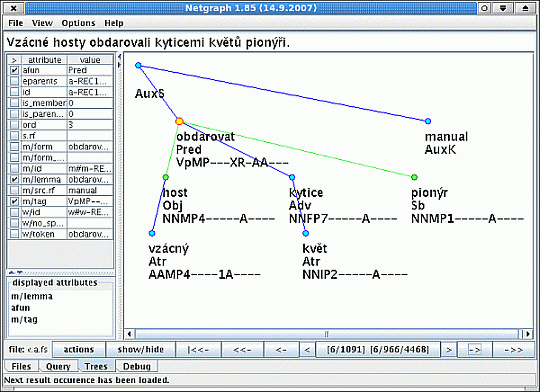
Users always use the client side of the Netgraph application. The client connects to the public server quest.ms.mff.cuni.cz through the 2001 port . Another possibility for the user is to install the server part of the application and then search the corpus offline.
The data and applications for the morphological and syntactical analysis of the Czech texts were developed simultaneously. The CD-ROM contains two fundamental morphological applications – morphological analysis and tagging – and one syntactical application – parsing. Also, the procedure for tokenisation is included.
Tokenistion is the process of splitting the given text into word tokens. Its result is so-called “vertical” which means it is a file containing each word or punctuation on a separate line. The term tokenization is often used for both splitting the text into words and segmentation, i.e. marking sentence and paragraph boundaries. Our tokenisation procedure also segments the text.
However we understand tokenisation even more broadly – the procedure vertically converts into the CSTS format (see Section 3.2.1). This conversion includes: adding the file header to the beginning of the vertical column and marking each word with a simple tag distinguishing the word properties that are clear straight from the orthographic form of the word. Punctuation, digits or words containing digits are especially marked. The upper case words and words beginning with upper case letters are marked with special tags, too. The resulting vertical column in the CSTS format serves as the input for further processing.
The morphological analysis evaluates individual word forms and determines lemmas as well as possible morphological interpretations for the word form.
The morphological analysis is based on the morphological dictionary containing part of speech information on Czech word forms. Each word form is assigned a morphological tag describing the morphological characteristics of the word form. The morphological dictionary used for the analysis contains additional information for many lemmas – style, semantics or derivational information. The lemmas of abbreviations are often enriched by comments referring to the explanatory text in Attachment B.
Due to the high homonymy of the Czech language, most word forms can be assigned more morphological tags or even more lemmas. For example, the word form pekla has two lemmas – noun peklo (hell) and verb péci (to bake). Both lemmas generate several tags for the given word form. The morphological analysis compares the possible word forms from the whole corpus to the word forms contained in the morphological dictionary. The corresponding lemmas and tags are assigned to the given word form in case they match. Therefore a set of pairs “lemma – morphological tag” is the result of the morphological analysis for each word form.
The morphological analysis is followed by tagging (also called disambiguation). In this phase the right combination of the lemma and tag for the given context is selected from the set of all possible lemmas and tags. Regarding the character of the task, it is impossible to generate a method of tagging that would function with 100 percent accuracy. The program carrying out the tagging is called tagger. The tagger application included on the CD-ROM is based on the Hidden Markov Model (HMM) and implements the use of the averaged perceptron statistical method (Collins, 2002): The method is statistically based. A text that contains the set of all possible morphological tags and lemmas for every word (the output from the morphological analysis) is the input for the tagger. In the output, the tagger defines this dataset with an unambiguously determined tag and its corresponding lemma. The tagger was trained on data in the PDT 2.0.
After tagging the next step of text processing is parsing. The parsing procedure assigns each word in the sentence its syntactical dependency on another word along with its analytical function. The program carrying out the parsing is called parser. The parser included in the CD-ROM is based on the same methodology as the tagger. The input of the parser is a text consisting of words labelled by a single pair lemma-tag. The output is a tree structure labelled by analytical functions for each sentence. The parser has been trained on the PDT 2.0 training data.
The script tool_chain is provided for the user’s convenience. This script uses basic switches to run the needed tool. For the switches documentation see Table 3.12. Concatenating more switches enables running more tools in sequence.
Example: The following command morphologically analyses raw text: tool_chain -tA
Note: When working with files in the PML format, the directory containing the input file of the tool_chain script must contain all files linked from the processed file. In case the m-file serves as input, it has to be “accompanied” by the corresponding w-file.
Table 3.12. Script tool_chain
| Parameter | Processing type | Input file format | Output file format |
|---|---|---|---|
-t | Tokenisation | Raw text | CSTS |
-A | Morphological analysis | CSTS | PML m-file, CSTS |
-T | Tagging | PML m-file, CSTS (morphological analysis output) | PML m-file, CSTS |
-P | Parsing | PML m-file, CSTS | PML a-file, CSTS |
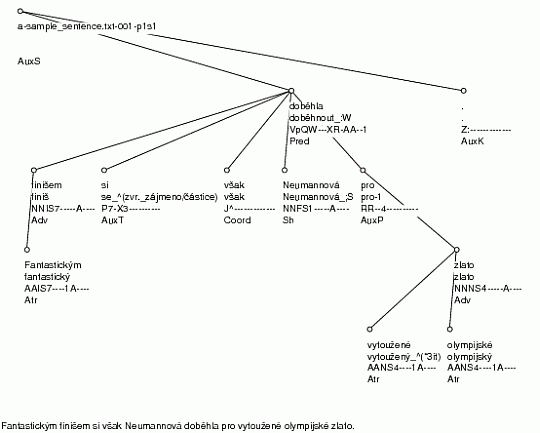
Example: Let´s have a look at the analysis of Fantastickým finišem si však Neumannová doběhla pro vytoužené olympijské zlato (E.: Neumannova powered down the final straight to win the longed-for gold). The results of the morphological analysis (run by the command tool_chain -tA) and tagging (run by the command tool_chain -T) is summarized Table 3.13. In case more possible lemmas exist for the given word form (e. g. the word form si is analysed either as the verb být (to be) or as the reflexive particle se) the word form possibilities are separated with the pipe symbol “|”. To spare the reader from searching for errors the tagger itself made, we confirm that there are no errors in this output. Figure 3.7 shows the parsing result (parsing run by the command tool_chain -P). Each node of the tree displays a word form, disambiguated lemma, disambiguated morphological tag and analytic function. To spare the reader from searching for errors the parser has made, we confirm that there are no errors in this output.
Table 3.13. An example of text treated with morphological analysis and tagging
| Text | Morphological analysis | Tagging |
|---|---|---|
| Fantastickým | fantastický AAFP3----1A---- AAIP3----1A---- AAIS6----1A---7 AAIS7----1A---- AAMP3----1A---- AAMS6----1A---7 AAMS7----1A---- AANP3----1A---- AANS6----1A---7 AANS7----1A---- | fantastický AAIS7----1A---- |
| finišem | finiš NNIS7-----A---- | finiš NNIS7-----A---- |
| si | být VB-S---2P-AA--7| se_ ^(zvr._zájmeno/částice) P7-X3---------- | se_^(zvr._zájmeno/částice) P7-X3---------- |
| však | však J^------------- | však J^------------- |
| Neumannová | Neumannová_;S NNFS1-----A---- NNFS5-----A---- | Neumannová_;S NNFS1-----A---- |
| doběhla | doběhnout_:W VpQW---XR-AA--1 | doběhnout_:W VpQW---XR-AA--1 |
| pro | pro-1 RR--4---------- | pro-1 RR--4---------- |
| vytoužené | vytoužený_^(*3it) AAFP1----1A---- AAFP4----1A---- AAFP5----1A---- AAFS2----1A---- AAFS3----1A---- AAFS6----1A---- AAIP1----1A---- AAIP4----1A---- AAIP5----1A---- AAMP4----1A---- AANS1----1A---- AANS4----1A---- AANS5----1A---- | vytoužený_^(*3it) AANS4----1A---- |
| olympijské | olympijský AAFP1----1A---- AAFP4----1A---- AAFP5----1A---- AAFS2----1A---- AAFS3----1A---- AAFS6----1A---- AAIP1----1A---- AAIP4----1A---- AAIP5----1A---- AAMP4----1A---- AANS1----1A---- AANS4----1A---- AANS5----1A---- | olympijský A ANS4----1A---- |
| zlato | zlato NNNS1-----A---- NNNS4-----A---- NNNS5-----A---- | zlato NNNS4-----A---- |
| . | . Z:------------- | . Z:------------- |
We recommend the users to test the tools by running the script tool_chain -tA on an arbitrary Czech text. The results of the script can be opened in the LAW tool, which also enables the disambiguation of the assigned tags.
Run the script tool_chain -P on the manually disambiguated file. The result of the script can be opened in the TrEd tool, which also enables correcting the dependencies and analytic functions.