Fisher Spanish - Transcripts
| Item Name: | Fisher Spanish - Transcripts |
| Author(s): | David Graff, Shudong Huang, Ingrid Cartagena, Kevin Walker, Christopher Cieri |
| LDC Catalog No.: | LDC2010T04 |
| ISBN: | 1-58563-537-5 |
| ISLRN: | 190-555-041-041-7 |
| DOI: | https://doi.org/10.35111/s30q-sn19 |
| Release Date: | February 22, 2010 |
| Member Year(s): | 2010 |
| DCMI Type(s): | Text |
| Data Source(s): | transcribed speech, telephone conversations |
| Application(s): | topic detection and tracking, spoken dialogue modeling |
| Language(s): | Spanish |
| Language ID(s): | spa |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2010T04 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Graff, David, et al. Fisher Spanish - Transcripts LDC2010T04. Web Download. Philadelphia: Linguistic Data Consortium, 2010. |
| Related Works: | View |
Introduction
Fisher Spanish - Transcripts was developed by LDC and contains full orthographic transcripts of the telephone speech in Fisher Spanish - Speech (LDC2010S01). Transcripts cover roughly 163 hours of telephone speech from 136 native Caribbean Spanish and non-Caribbean Spanish speakers.
The Fisher telephone conversation collection protocol was created at LDC to address a critical need of developers trying to build robust automatic speech recognition (ASR) systems. Previous collection protocols, such as CALLFRIEND and Switchboard-II and the resulting corpora, have been adapted for ASR research but were in fact developed for language and speaker identification respectively. Although the CALLHOME protocol and corpora were developed to support ASR technology, they feature small numbers of speakers making telephone calls of relatively long duration with narrow vocabulary across the collection. CALLHOME conversations are challengingly natural and intimate. Under the Fisher protocol, a very large number of participants each make a few calls of short duration speaking to other participants, whom they typically do not know, about assigned topics. This maximizes inter-speaker variation and vocabulary breadth although it also increases formality.
Previous protocols such as CALLHOME, CALLFRIEND and Switchboard relied upon participant activity to drive the collection. Fisher is unique in being platform driven rather than participant driven. Participants who wish to initiate a call may do so; however the collection platform initiates the majority of calls. Participants need only answer their phones at the times they specified when registering for the study.
To encourage a broad range of vocabulary, Fisher participants are asked to speak on an assigned topic which is selected at random from a list, which changes every 24 hours and which is assigned to all subjects paired on that day. Some topics are inherited or refined from previous Switchboard studies while others were developed specifically for the Fisher protocol.
In collecting data for this corpus, attempts were made to provide a representative distribution of subjects across a variety of demographic categories including: gender, age, dialect region, and education level.
This corpus joins other Fisher corpora: Arabic CTS Levantine Fisher Training Data Set 3 (LDC2005S07, LDC2005T03), Fisher English Training Part 2 (LDC2005S13, LDC2005T19), Fisher English Training Speech Part 1 (LDC2004S13, LDC2004T19), and Fisher Levantine Arabic Conversational Telephone Speech (LDC2007S02, LDC2007T04)
Data
The transcript files are in plain-text, tab-delimited format (tdf) with UTF-8 character encoding. They were created with the LDC-developed transcription tool "XTrans", which allowed for improved handling of multi-channel audio and overlapping speakers. XTrans is available from LDC.
Transcribers followed LDC's Transcription Guidelines (NQTR), which are included with the documentation for this release.
The first line of each transcript file provides the column headings; the next two lines are "comments" that can be ignored (these are used by XTrans; they are distinguished from non-comment lines by having an initial semicolon ";"). Actual transcript data, with time stamps, channel number, transcript text and additional information, begins at line 4 of each transcript file.
Fisher Spanish - Speech (LDC2010S01) provides the digital audio used as the basis for the transcriptions in this corpus, in the form of 2-channel mu-law sample data with 8000 samples per second (as captured from the public telephone network), for 819 telephone conversations of 10 to 12 minutes in duration. The audio files are in NIST SPHERE format (1024-byte ASCII file headers).
Native speakers of Caribbean Spanish and non-Caribbean Spanish were recruited from within the continental United States and Puerto Rico. The following tables provide an overview of the demographics of the participants. The Subjects Table file, provided in the documentation, may be used to answer questions about specific combinations of participant characteristics (including level of participation).
|
|
|
|
|
|
Samples
Please examine this sample to see an example of the data in this corpus.
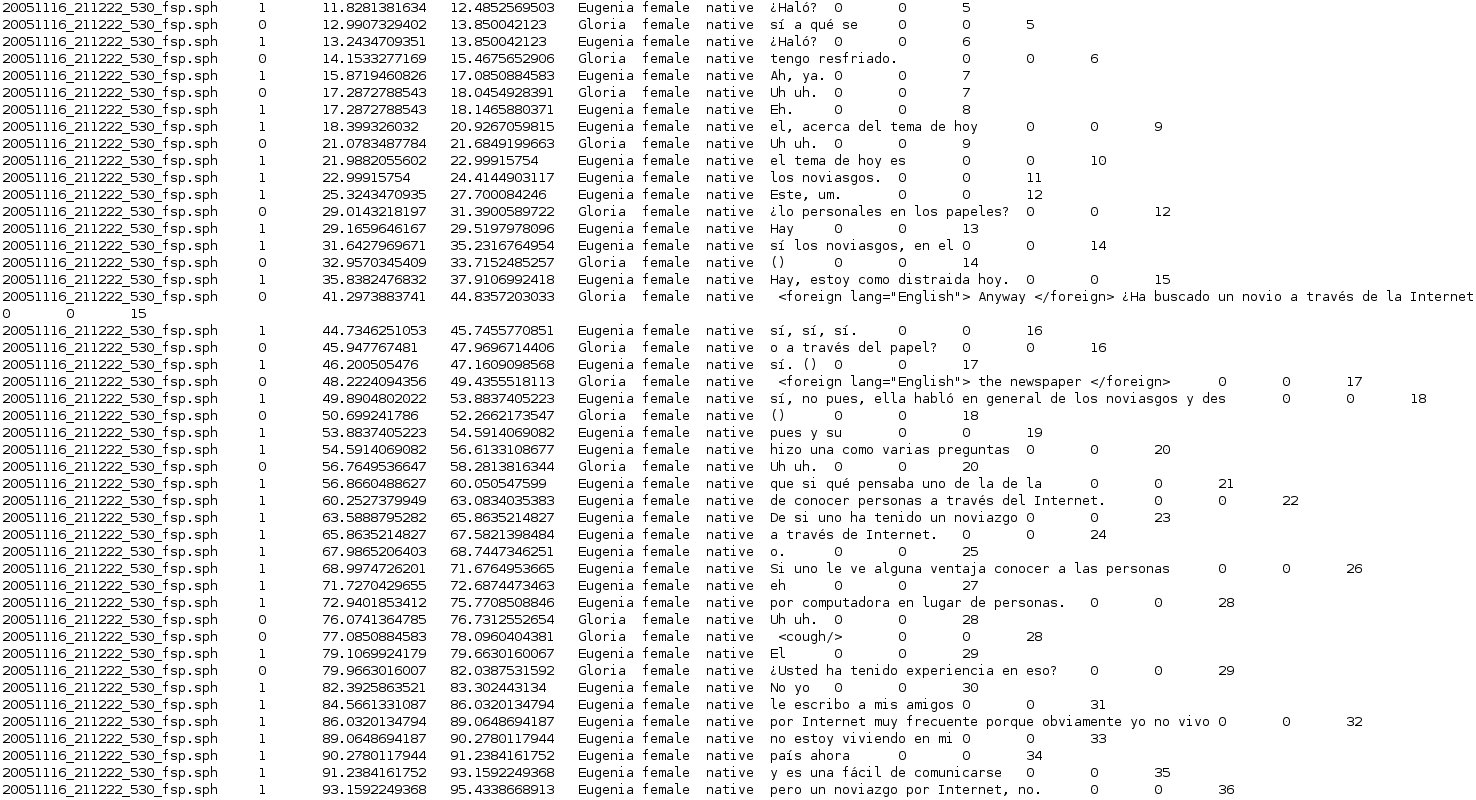{kind=link}
Updates
12/22/10 - The online documentation for this data now contains a new version of the "fsp_call.tbl", in which an extra column has been included in each row to identify the topic number used in each call. A copy of the topic list in English is also available under fsp06_topics_in_english.txt.