Annotated English Gigaword
| Item Name: | Annotated English Gigaword |
| Author(s): | Courtney Napoles, Matthew R. Gormley, Benjamin Van Durme |
| LDC Catalog No.: | LDC2012T21 |
| ISBN: | 1-58563-629-0 |
| ISLRN: | 335-916-789-872-0 |
| DOI: | https://doi.org/10.35111/mv9t-vv26 |
| Release Date: | November 15, 2012 |
| Member Year(s): | 2012 |
| DCMI Type(s): | Text |
| Data Source(s): | newswire |
| Project(s): | GALE |
| Application(s): | information extraction, information retrieval, language modeling, parsing |
| Language(s): | English |
| Language ID(s): | eng |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2012T21 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Napoles, Courtney, Matthew Gormley, and Benjamin Van Durme. Annotated English Gigaword LDC2012T21. Web Download. Philadelphia: Linguistic Data Consortium, 2012. |
| Related Works: | View |
Introduction
Annotated English Gigaword was developed by Johns Hopkins University's Human Language Technology Center of Excellence. It adds automatically-generated syntactic and discourse structure annotation to English Gigaword Fifth Edition (LDC2011T07) and also contains an API and tools for reading the dataset's XML files. The goal of the annotation is to provide a standardized corpus for knowledge extraction and distributional semantics which enables broader involvement in large-scale knowledge-acquisition efforts by researchers.
Data
Annotated English Gigaword contains the nearly ten million documents (over four billion words) of the original English Gigaword Fifth Edition from seven news sources:
- Agence France-Presse, English Service (afp_eng)
- Associated Press Worldstream, English Service (apw_eng)
- Central News Agency of Taiwan, English Service (cna_eng)
- Los Angeles Times/Washington Post Newswire Service (ltw_eng)
- Washington Post/Bloomberg Newswire Service (wpb_eng)
- New York Times Newswire Service (nyt_eng)
- Xinhua News Agency, English Service (xin_eng)
The following layers of annotation were added:
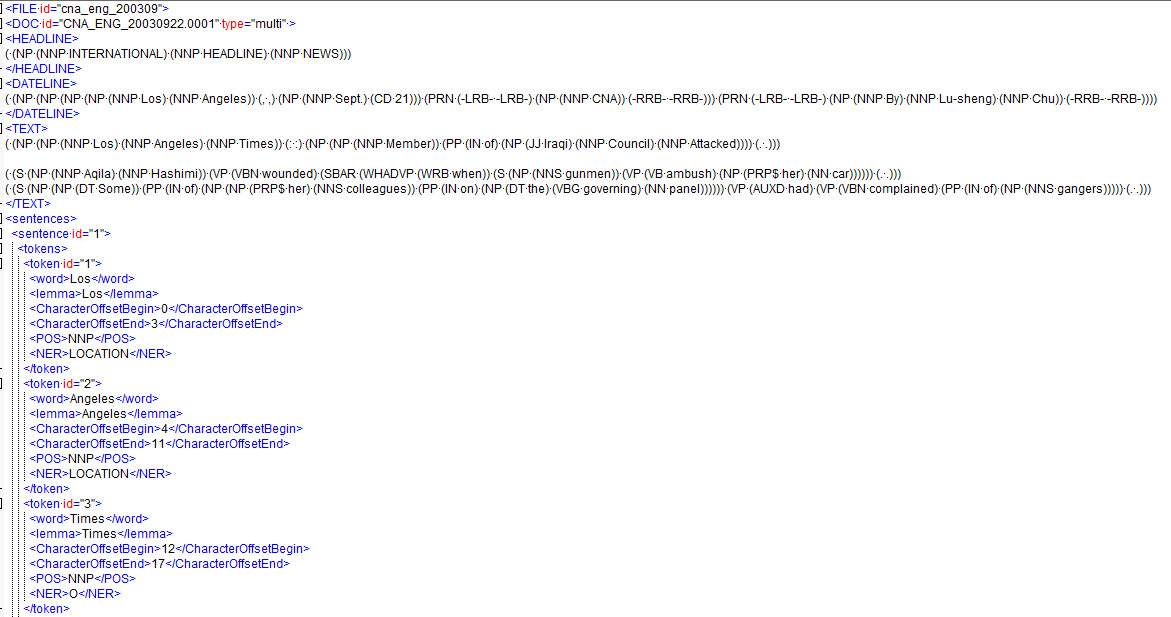
- Tokenized and segmented sentences
- Treebank-style constituent parse trees
- Syntactic dependency trees
- Named entities
- In-document coreference chains
The annotation was performed in a three-step process: (1) the data was preprocessed and sentences selected for annotation (sentences with more than 100 tokens were excluded) (2) syntactic parses were derived and (3) the parsed output was post-processed to derive syntactic dependencies, named entities and coreference chains. Over 183 million sentences were parsed.
The data is stored in a form similar to the gigaword SGML format with XML annotations containing the additional markup. The included API provides object representations for the contents of the XML files.
Samples
Please the link for a sample.
{kind=link}
Additional Licensing Information
Any 2011 member organization that licensed English Gigaword Fifth Edition (LDC2011T07) may request a no-cost copy of Annotated English Gigaword. Any non-member organization that licensed English Gigaword Fifth Edition may request a copy of Annotated English Gigaword for a $150 fee. Please contact ldc@ldc.upenn.edu for licensing or with any additional questions.
Updates
None at this time.