Concretely Annotated English Gigaword
| Item Name: | Concretely Annotated English Gigaword |
| Author(s): | Francis Ferraro, Max Thomas, Matthew R. Gormley, Travis Wolfe, Craig Harman, Benjamin Van Durme |
| LDC Catalog No.: | LDC2018T20 |
| ISBN: | 1-58563-861-7 |
| ISLRN: | 309-427-947-277-9 |
| DOI: | https://doi.org/10.35111/a802-nz06 |
| Release Date: | October 15, 2018 |
| Member Year(s): | 2018 |
| DCMI Type(s): | Text |
| Data Source(s): | newswire |
| Project(s): | GALE |
| Application(s): | coreference resolution, event detection, information extraction, information retrieval, language modeling, parsing |
| Language(s): | English |
| Language ID(s): | eng |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2018T20 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Ferraro, Francis, et al. Concretely Annotated English Gigaword LDC2018T20. Web Download. Philadelphia: Linguistic Data Consortium, 2018. |
| Related Works: | View |
Introduction
Concretely Annotated English Gigaword was developed by Johns Hopkins University's Human Language Technology Center of Excellence (JHU). It adds multiple kinds and instances of automatically-generated syntactic, semantic and coreference annotations to English Gigaword Fifth Edition (LDC2011T07).
Concrete is a schema for representing structured, hierarchical and overlapping linguistic annotations. This release provides multiple tool outputs producing the same annotation types as different annotation theories under a shared tokenization.
The Linguistic Data Consortium (LDC) has also released Annotated English Gigaword (LDC2012T21), earlier work by JHU researchers to create a standardized corpus for knowledge extraction and distributional semantics by using then-state of the art tools to add automatically-generated syntactic and discourse structure annotation to English Gigaword Fifth Edition.
Data
Concretely Annotated English Gigaword contains the nearly ten million documents (over four billion words) of the original English Gigaword Fifth Edition which consists of newswire stories from seven sources collected by LDC between 1994-2010.
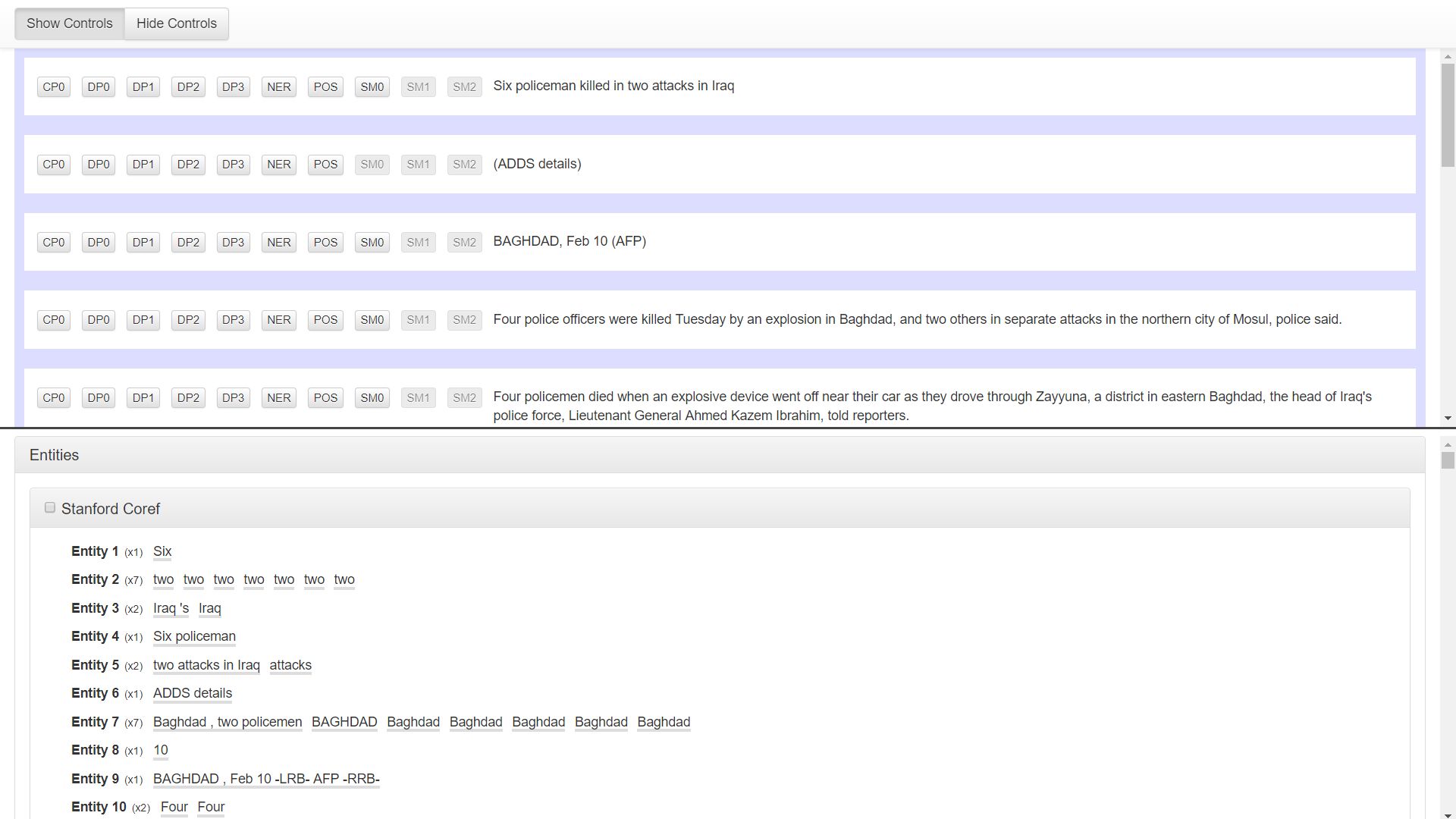
The following layers of annotation were added under the Concrete schema:
- Segmented sentences and Penn Treebank-style tokenized words
- Treebank-style constituent parse trees
- Four different syntactic dependency trees
- Named entities
- Part of speech tags
- Lemmas
- In-document entity coreference chains
- Three different frame semantic parses
The data is stored in a binary form called Concrete, which is based upon Apache Thrift. Concrete can be read and written in many common programming languages, like Java, Python, Javascript and C++. Concrete also has a number of utilities to easily access and view the data in human-readable forms.
Samples
Please view the following samples:
{kind=link}
{kind=link}
{kind=link}
Reference
Users of this corpus must cite the following paper:
Francis Ferraro, Max Thomas, Matthew Gormley, Travis Wolfe, Craig Harman, and Benjamin Van Durme. "Concretely Annotated Corpora." In The Proceedings of the NIPS Workshop on Automated Knowledge Base Construction (AKBC). NIPS Workshop 2014.
Additional Licensing Instructions
Any organization that licensed English Gigaword Fifth Edition (LDC2011T07) or Annotated English Gigaword (LDC2012T21) may request a copy of Concretely Annotated English Gigaword (LDC2018T20) for a $150 fee. Contact ldc@ldc.upenn.edu for licensing.