GALE Arabic-English Parallel Aligned Treebank -- Broadcast News Part 1
| Item Name: | GALE Arabic-English Parallel Aligned Treebank -- Broadcast News Part 1 |
| Author(s): | Xuansong Li, Stephen Grimes, Safa Ismael, Stephanie Strassel, Mohamed Maamouri, Ann Bies |
| LDC Catalog No.: | LDC2013T14 |
| ISBN: | 1-58563-649-5 |
| ISLRN: | 405-302-338-505-1 |
| DOI: | https://doi.org/10.35111/9npx-fe20 |
| Release Date: | July 15, 2013 |
| Member Year(s): | 2013 |
| DCMI Type(s): | Text |
| Data Source(s): | broadcast news |
| Project(s): | GALE |
| Application(s): | machine translation, information detection, cross-lingual information retrieval, automatic content extraction |
| Language(s): | English, Standard Arabic, Arabic |
| Language ID(s): | eng, arb, ara |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2013T14 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Li, Xuansong, et al. GALE Arabic-English Parallel Aligned Treebank -- Broadcast News Part 1 LDC2013T14. Web Download. Philadelphia: Linguistic Data Consortium, 2013. |
| Related Works: | View |
GALE Arabic-English Parallel Aligned Treebank -- Broadcast News Part 1 was developed by the Linguistic Data Consortium (LDC) and contains 115,826 tokens of word aligned Arabic and English parallel text with treebank annotations. This material was used as training data in the DARPA GALE (Global Autonomous Language Exploitation) program.
Parallel aligned treebanks are treebanks annotated with morphological and syntactic structures aligned at the sentence level and the sub-sentence level. Such data sets are useful for natural language processing and related fields, including automatic word alignment system training and evaluation, transfer-rule extraction, word sense disambiguation, translation lexicon extraction and cultural heritage and cross-linguistic studies. With respect to machine translation system development, parallel aligned treebanks may improve system performance with enhanced syntactic parsers, better rules and knowledge about language pairs and reduced word error rate.
In this release, the source Arabic data was translated into English. Arabic and English treebank annotations were performed independently. The parallel texts were then word aligned. The material in this corpus corresponds to a portion of the Arabic treebanked data in Arabic Treebank - Broadcast News v1.0 (LDC2012T07).
Data
The source data consists of Arabic broadcast news programming collected by LDC in 2005 and 2006 from Alhurra, Aljazeera and Dubai TV. All data is encoded as UTF-8. A count of files, words, tokens and segments is below.
| Language | Files | Words | Tokens | Segments |
| Arabic | 28 | 89,213 | 115,826 | 4,824 |
Note: Word count is based on the untokenized Arabic source. Token count is based on the ATB-tokenized Arabic source.
The purpose of the GALE word alignment task was to find correspondences between words, phrases or groups of words in a set of parallel texts. Arabic-English word alignment annotation consisted of the following tasks:
- Identifying different types of links: translated (correct or incorrect) and not translated (correct or incorrect)
- Identifying sentence segments not suitable for annotation, e.g., blank segments, incorrectly-segmented segments, segments with foreign languages
- Tagging unmatched words attached to other words or phrases
This release contains four types of files - raw, tokenized, treebank, and wa. The raw format contains the original Arabic and English sentences without any annotation. The tokenized format is the treebank tokenized version of the raw data which may contain Empty Category tokens (treebank leaves that have the POS label -NONE-). The treebank and wa files are treebank and word alignment annotations on the tokenized files.
Samples
Please view the below samples.
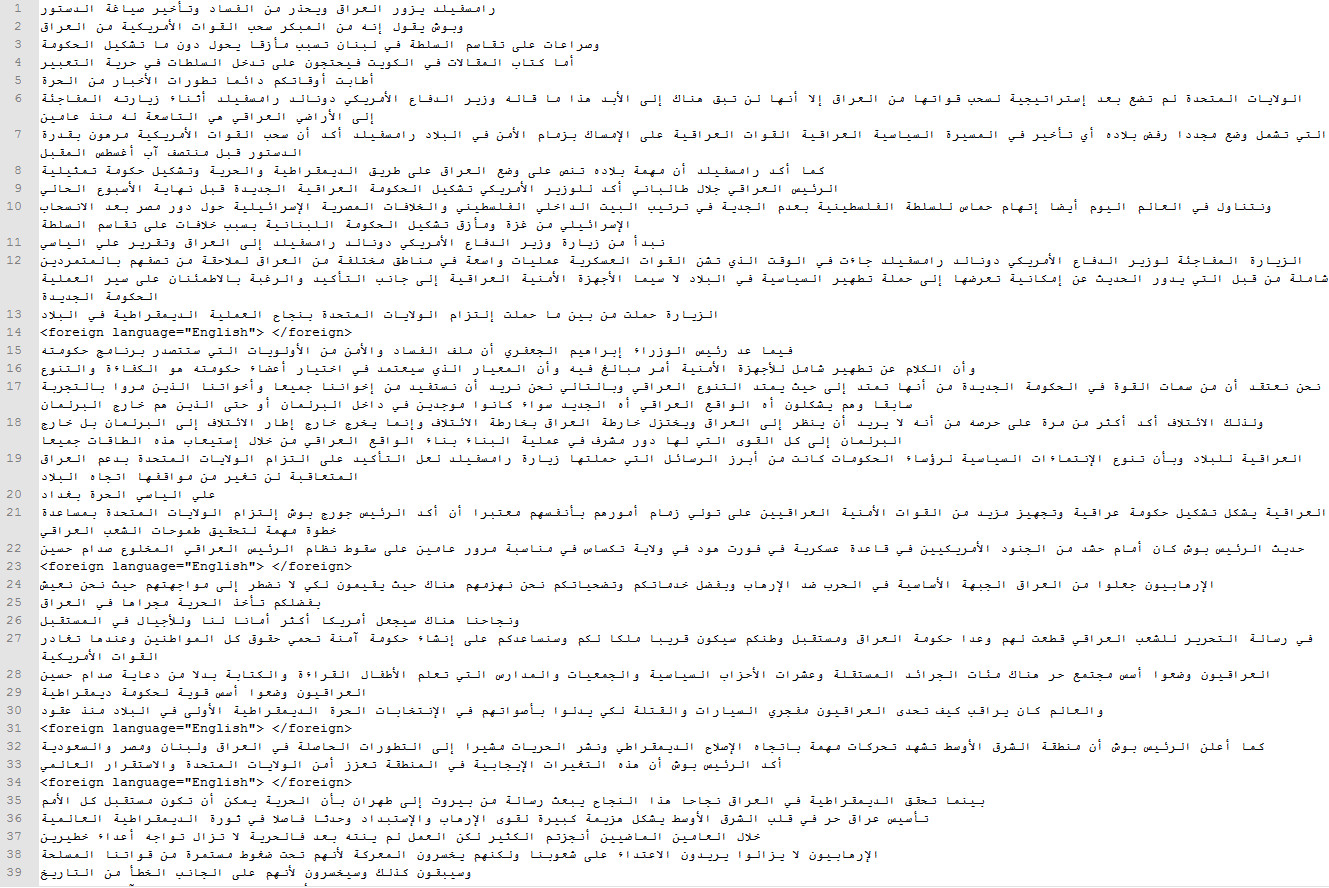{kind=link}
{kind=link}
{kind=link}
Sponsorship
This work was supported in part by the Defense Advanced Research Projects Agency, GALE Program Grant No. HR0011-06-1-0003. The content of this publication does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.
Updates
None at this time.