GALE Arabic-English Word Alignment -- Broadcast Training Part 2
| Item Name: | GALE Arabic-English Word Alignment -- Broadcast Training Part 2 |
| Author(s): | Xuansong Li, Stephen Grimes, Safa Ismael, Stephanie Strassel |
| LDC Catalog No.: | LDC2014T22 |
| ISBN: | 1-58563-691-6 |
| ISLRN: | 901-500-716-588-1 |
| DOI: | https://doi.org/10.35111/2aaj-dj35 |
| Release Date: | October 15, 2014 |
| Member Year(s): | 2014 |
| DCMI Type(s): | Text |
| Data Source(s): | broadcast conversation, broadcast news |
| Project(s): | GALE |
| Application(s): | automatic content extraction, content-based retrieval, machine translation, tagging |
| Language(s): | Standard Arabic, Arabic, English |
| Language ID(s): | arb, ara, eng |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2014T22 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Li, Xuansong, et al. GALE Arabic-English Word Alignment -- Broadcast Training Part 2 LDC2014T22. Web Download. Philadelphia: Linguistic Data Consortium, 2014. |
| Related Works: | View |
Introduction
GALE Arabic-English Word Alignment -- Broadcast Training Part 2 was developed by the Linguistic Data Consortium (LDC) and contains 215,923 tokens of word aligned Arabic and English parallel text enriched with linguistic tags. This material was used as training data in the DARPA GALE (Global Autonomous Language Exploitation) program.
Some approaches to statistical machine translation include the incorporation of linguistic knowledge in word aligned text as a means to improve automatic word alignment and machine translation quality. This is accomplished with two annotation schemes: alignment and tagging. Alignment identifies minimum translation units and translation relations by using minimum-match and attachment annotation approaches. A set of word tags and alignment link tags are designed in the tagging scheme to describe these translation units and relations. Tagging adds contextual, syntactic and language-specific features to the alignment annotation.
Other releases available in this series are:
- GALE Chinese-English Word Alignment and Tagging Training Part 1 -- Newswire and Web (LDC2012T16)
- GALE Chinese-English Word Alignment and Tagging Training Part 2 -- Newswire (LDC2012T20)
- GALE Chinese-English Word Alignment and Tagging Training Part 3 -- Web (LDC2012T24)
- GALE Chinese-English Word Alignment and Tagging Training Part 4 -- Web (LDC2013T05)
- GALE Chinese-English Word Alignment and Tagging -- Broadcast Training Part 1 (LDC2013T23)
- GALE Arabic-English Word Alignment Training Part 1 -- Newswire and Web (LDC2014T05)
- GALE Arabic-English Word Alignment Training Part 2 -- Newswire (LDC2014T10)
- GALE Arabic-English Word Alignment Training Part 3 -- Web (LDC2014T14)
- GALE Arabic-English Word Alignment -- Broadcast Training Part 1 (LDC2014T19)
Data
This release consists of Arabic source broadcast news and broadcast conversation data collected by LDC from 2007-2009. The distribution by genre, words, tokens and segments appears below:
| Language | Genre | Files | Words | Tokens | Segments |
|---|---|---|---|---|---|
| Arabic | BC | 369 | 97,514 | 129,233 | 7,941 |
| Arabic | BN | 40 | 70,635 | 86,400 | 3,752 |
| Totals | 409 | 168,149 | 215,923 | 11,693 |
Note that word count is based on the untokenized Arabic source, and token count is based on the tokenized Arabic source.
The Arabic word alignment tasks consisted of the following components:
- Normalizing tokenized tokens as needed
- Identifying different types of links
- Identifying sentence segments not suitable for annotation
- Tagging unmatched words attached to other words or phrases
Samples
Please view the following samples:
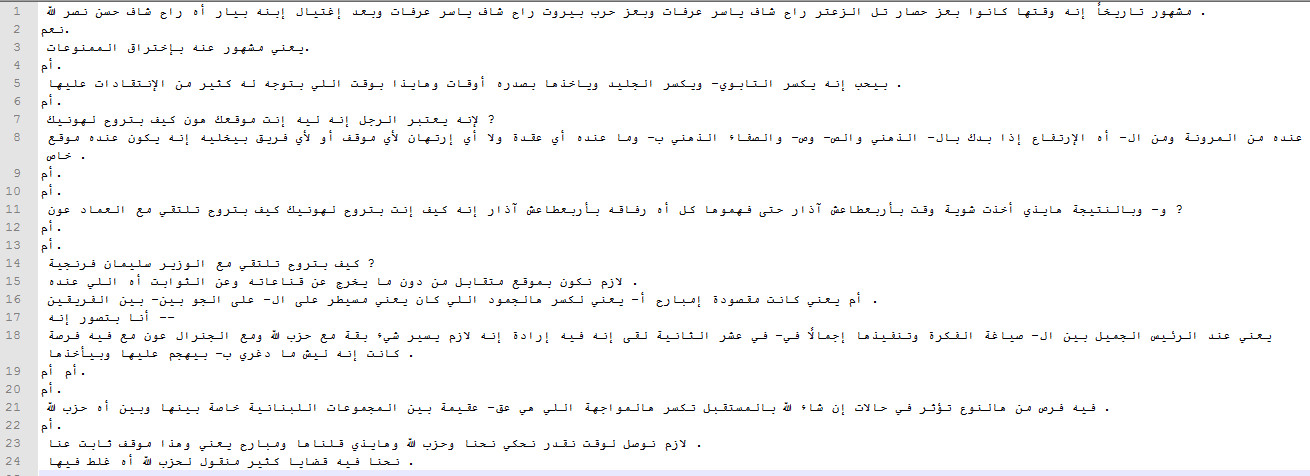{kind=link}
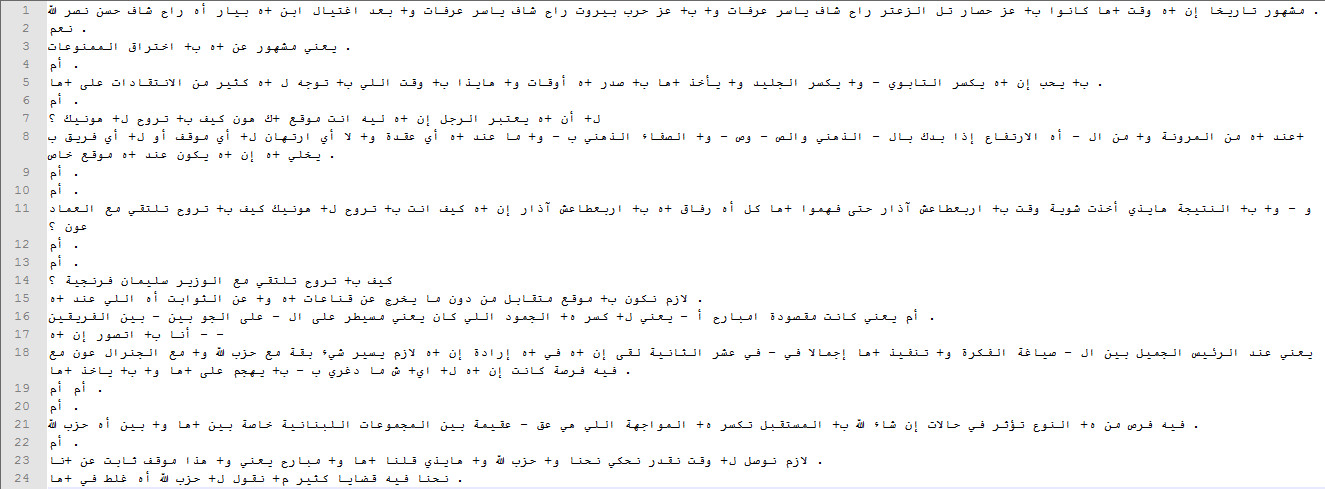{kind=link}
Sponsorship
This work was supported in part by the Defense Advanced Research Projects Agency, GALE Program Grant No. HR0011-06-1-0003. The content of this publication does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.
Updates
None at this time.