MADCAT Chinese Pilot Training Set
| Item Name: | MADCAT Chinese Pilot Training Set |
| Author(s): | Song Chen, David Lee, Stephen Grimes, Dave Doermann, Stephanie Strassel |
| LDC Catalog No.: | LDC2014T13 |
| ISBN: | 1-58563-680-0 |
| ISLRN: | 931-416-601-272-1 |
| DOI: | https://doi.org/10.35111/anvy-qh36 |
| Release Date: | June 16, 2014 |
| Member Year(s): | 2014 |
| DCMI Type(s): | Text, StillImage |
| Data Source(s): | newswire, newsgroups, weblogs |
| Project(s): | MADCAT |
| Application(s): | handwriting recognition, machine translation |
| Language(s): | Mandarin Chinese |
| Language ID(s): | cmn |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2014T13 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Chen, Song, et al. MADCAT Chinese Pilot Training Set LDC2014T13. Web Download. Philadelphia: Linguistic Data Consortium, 2014. |
| Related Works: | View |
Introduction
MADCAT (Multilingual Automatic Document Classification Analysis and Translation) Chinese Pilot Training Set contains all training data created by the Linguistic Data Consortium (LDC) to support a Chinese pilot collection in the DARPA MADCAT Program. The data in this release consists of handwritten Chinese documents, scanned at high resolution and annotated for the physical coordinates of each line and token. Digital transcripts and English translations of each document are also provided, with the various content and annotation layers integrated in a single MADCAT XML output.
The goal of the MADCAT program was to automatically convert foreign text images into English transcripts. MADCAT Chinese pilot data was collected from Chinese source documents in three genres: newswire, weblog and newsgroup text. Chinese speaking "scribes" copied documents by hand, following specific instructions on writing style (fast, normal, careful), writing implement (pen, pencil) and paper (lined, unlined). Prior to assignment, source documents were processed to optimize their appearance for the handwriting task, which resulted in some original source documents being broken into multiple "pages" for handwriting. Each resulting handwritten page was assigned to up to five independent scribes, using different writing conditions.
The handwritten, transcribed documents were next checked for quality and completeness, then each page was scanned at a high resolution (600 dpi, greyscale) to create a digital version of the handwritten document. The scanned images were then annotated to indicate the physical coordinates of each line and token. Explicit reading order was also labeled, along with any errors produced by the scribes when copying the text.
The final step was to produce a unified data format that takes multiple data streams and generates a single MADCAT XML output file which contains all required information. The resulting madcat.xml file contains distinct components: a text layer that consists of the source text, tokenization and sentence segmentation; an image layer that consist of bounding boxes; a scribe demographic layer that consists of scribe ID and partition (train/test); and a document metadata layer.
LDC has also released:
- MADCAT Phase 1 Training Set (LDC2012T15)
- MADCAT Phase 2 Training Set (LDC2013T09)
- MADCAT Phase 3 Training Set (LDC2013T15)
Data
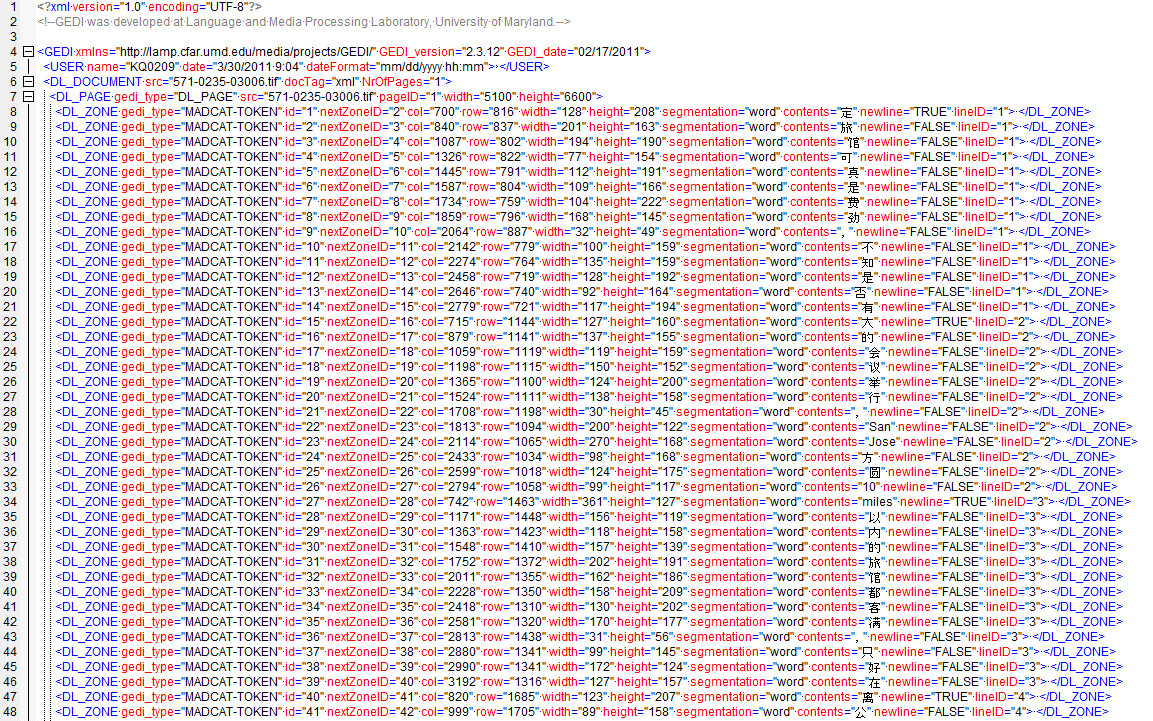
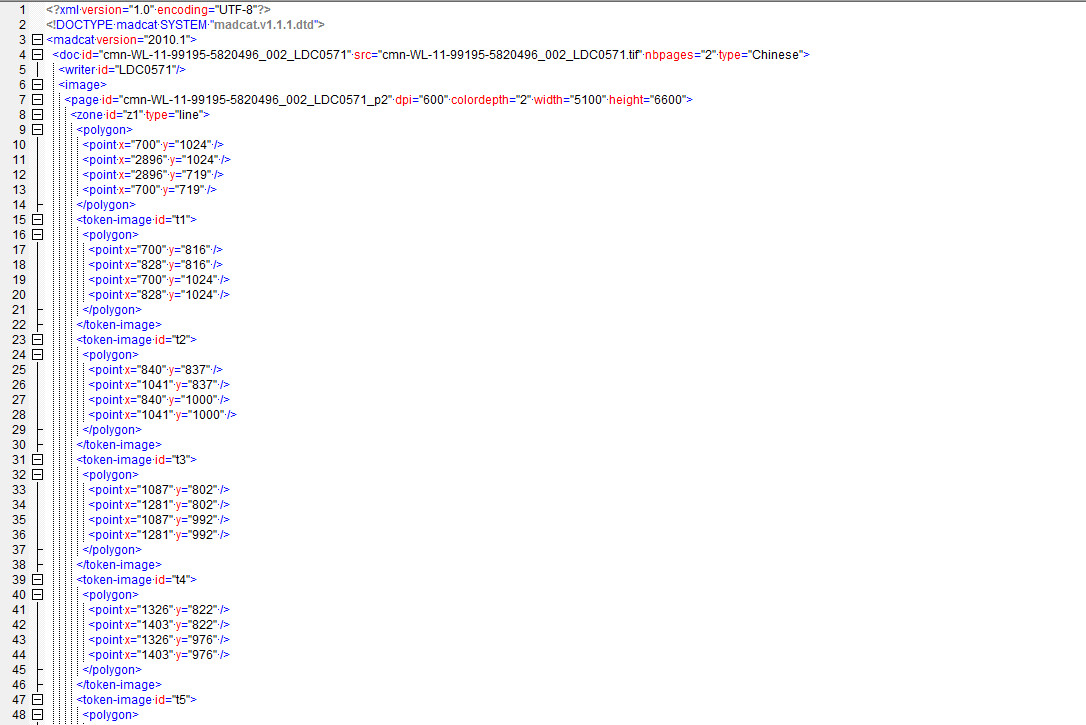
This release includes 22,284 annotation files in both GEDI XML and MADCAT XML formats (gedi.xml and .madcat.xml) along with their corresponding scanned image files in TIFF format. The annotation results in GEDI XML files include ground truth annotations and source transcripts.
Files are named as follows:
- galeID_page#_scribeID.{tif|gedi.xml|madcat.xml}
Samples
Please view the following samples:
{kind=link}
{kind=link}
{kind=link}
Sponsorship
This work was supported in part by the Defense Advanced Research Projects Agency, MADCAT Program Grant No. HR0011-08-1-0004 and GALE Program Grant No. HR0011-06-1-0003. The content of this publication does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.
Updates
None at this time.