SenSem Lexicons
| Item Name: | SenSem Lexicons |
| Author(s): | Ana Fernández, Gloria Vázquez |
| LDC Catalog No.: | LDC2015L01 |
| ISBN: | 1-58563-713-0 |
| ISLRN: | 524-236-409-783-6 |
| DOI: | https://doi.org/10.35111/9xeb-gd36 |
| Release Date: | May 15, 2015 |
| Member Year(s): | 2015 |
| DCMI Type(s): | Text |
| Data Source(s): | fiction, newswire |
| Application(s): | language teaching, syntactic parsing |
| Language(s): | Catalan, Spanish |
| Language ID(s): | cat, spa |
| License(s): |
Creative Commons Attribution-NonCommercial-ShareAlike 3.0 (NFP, Non-Member)
LDC For-Profit Membership Agreement |
| Online Documentation: | LDC2015L01 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Fernández, Ana, and Gloria Vázquez. SenSem Lexicons LDC2015L01. Web Download. Philadelphia: Linguistic Data Consortium, 2015. |
| Related Works: | View |
Introduction
SenSem (Sentence Semantics) Lexicons was developed by GRIAL, the Linguistic Applications Inter-University Research Group that includes the following Spanish institutions: the Universitat Autonoma de Barcelona, the Universitat de Barcelona, the Universitat de Lleida and the Universitat Oberta de Catalunya. It contains feature descriptions for approximately 1,300 Spanish verbs and 1,300 Catalan verbs in the SenSem Databank (LDC2015T02). GRIAL's work focuses on resources for applied linguistics, including lexicography, translation and natural language processing.
Data
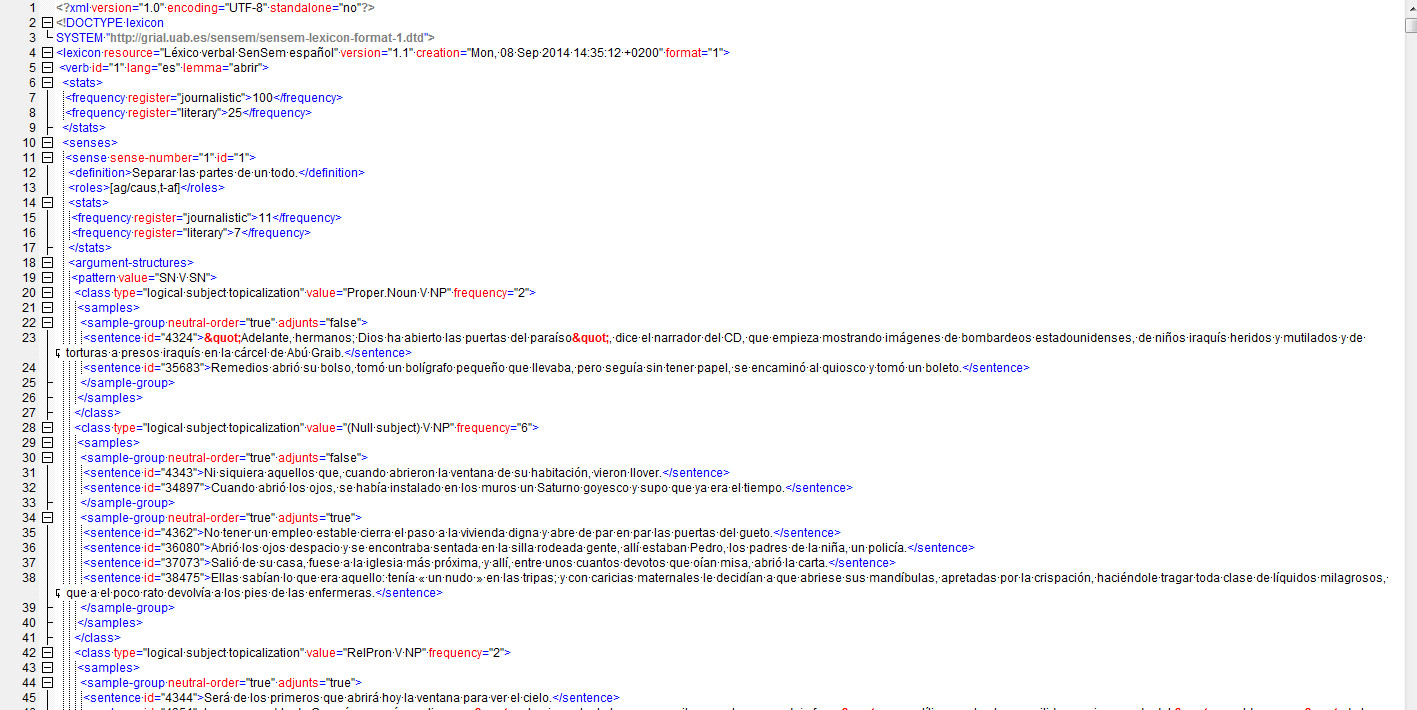
The verb features for each language consist of two groups: those codified manually, including definition, WordNet synset, Aktionsart, arguments and semantic functions; and those extracted automatically from the SenSem Databank. Among the latter are verb frequency, semantic construction, syntactic categories and constituent order. The verbs analyzed correspond to the 250 most frequent verbs in Spanish and 320 lemmas in Catalan. Further information about the SenSem project can be obtained from the GRIAL website at http://grial.uab.es/sensem/corpus.
Data is presented in a single XML file per language.
Samples
Please view this sample.
{kind=link}
Updates
None at this time.