NIST 2008 Open Machine Translation (OpenMT) Evaluation
| Item Name: | NIST 2008 Open Machine Translation (OpenMT) Evaluation |
| Author(s): | NIST Multimodal Information Group |
| LDC Catalog No.: | LDC2010T21 |
| ISBN: | 1-58563-567-7 |
| ISLRN: | 415-534-082-867-8 |
| DOI: | https://doi.org/10.35111/vkfb-pv51 |
| Release Date: | November 16, 2010 |
| Member Year(s): | 2010 |
| DCMI Type(s): | Text |
| Data Source(s): | newswire, web collection |
| Project(s): | NIST MT, GALE |
| Application(s): | machine translation |
| Language(s): | Urdu, English, Mandarin Chinese, Arabic, Chinese |
| Language ID(s): | urd, eng, cmn, ara, zho |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2010T21 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | NIST Multimodal Information Group. NIST 2008 Open Machine Translation (OpenMT) Evaluation LDC2010T21. Web Download. Philadelphia: Linguistic Data Consortium, 2010. |
| Related Works: | View |
Introduction
NIST 2008 Open Machine Translation (OpenMT) Evaluation, Linguistic Data Consortium (LDC) catalog number LDC2010T21 and isbn 1-58563-567-7, is a package containing source data, reference translations and scoring software used in the NIST 2008 OpenMT evaluation. It is designed to help evaluate the effectiveness of machine translation systems. The package was compiled and scoring software was developed by researchers at NIST, making use of broadcast, newswire and web data and reference translations collected and developed by LDC.
The objective of the NIST Open Machine Translation (OpenMT) evaluation series is to support research in, and help advance the state of the art of, machine translation (MT) technologies -- technologies that translate text between human languages. Input may include all forms of text. The goal is for the output to be an adequate and fluent translation of the original.
The MT evaluation series started in 2001 as part of the DARPA TIDES (Translingual Information Detection, Extraction) program. Beginning with the 2006 evaluation, the evaluations have been driven and coordinated by NIST as NIST OpenMT. These evaluations provide an important contribution to the direction of research efforts and the calibration of technical capabilities in MT. The OpenMT evaluations are intended to be of interest to all researchers working on the general problem of automatic translation between human languages. To this end, they are designed to be simple, to focus on core technology issues and to be fully supported. The 2008 task was to evaluate translation from Arabic to English, Chinese to English, English to Chinese (newswire only) and Urdu to English. Selected human reference translations and system translations for the NIST MT08 test sets are contained in NIST Open Machine Translation 2008 Evaluation (MT08) Selected Reference and System Translations LDC2010T01.
Additional information about these evaluations may be found at the NIST Open Machine Translation (OpenMT) Evaluation website.
Scoring Tools
This evaluation kit includes a single Perl script (mteval-v11b.pl) that may be used to produce a translation quality score for one (or more) MT systems. The script works by comparing the system output translation with a set of (expert) reference translations of the same source text. Comparison is based on finding sequences of words in the reference translations that match word sequences in the system output translation. More information on the evaluation algorithm may be obtained from the paper detailing the algorithm: BLEU: a Method for Automatic Evaluation of Machine Translation (Papineni et al, 2002).
The included scoring script was released with the original evaluation, intended for use with SGML-formatted data files, and is provided to ensure compatibility of user scoring results with results from the original evaluation. An updated scoring software package (mteval-v13a-20091001.tar.gz), with XML support, additional options and bug fixes, documentation, and example translations, may be downloaded from the NIST Multimodal Information Group Tools website.
Data
This release contains 494 documents with corresponding sets of four separate human expert reference translations. The source data is comprised of Arabic, Chinese, English and Urdu newswire, broadcast and weblog and newsgroup data collected by LDC in 2007. The newswire and broadcast material are from Asharq Al-Awsat (Arabic), Agence France-Presse (Arabic, Chinese, English), Al-Ahram (Arabic), Al Hayat (Arabic), Assabah (Arabic), An Nahar (Arabic), Al-Quds Al-Arabi (Arabic), Xinhua News Agency (Arabic, Chinese, English), Central News Service (Chinese), Guangming Daily (Chinese), People's Daily (Chinese), People's Liberation Army Daily (Chinese), British Broadcasting Corporation (Urdu), Daily Jang (Urdu), Pakistan News Service (Urdu), Voice of America (Urdu), Associated Press (English), New York Times (English) and Los Angeles Times/Washington Post Newswire Service (English).
For each language, the test set consists of two files: a source and a reference file. Each file contains four independent translations of the data set. The evaluation year, source language, test set (which, by default, is "evalset"), version of the data, and source vs. reference file (with the latter being indicated by "-ref") are reflected in the file name. A reference file contains four independent reference translations unless noted otherwise in the accompanying README.txt.
DARPA TIDES MT and NIST OpenMT evaluations used SGML-formatted test data until 2008 and XML-formatted test data thereafter. This files in this package are povided in both formats.
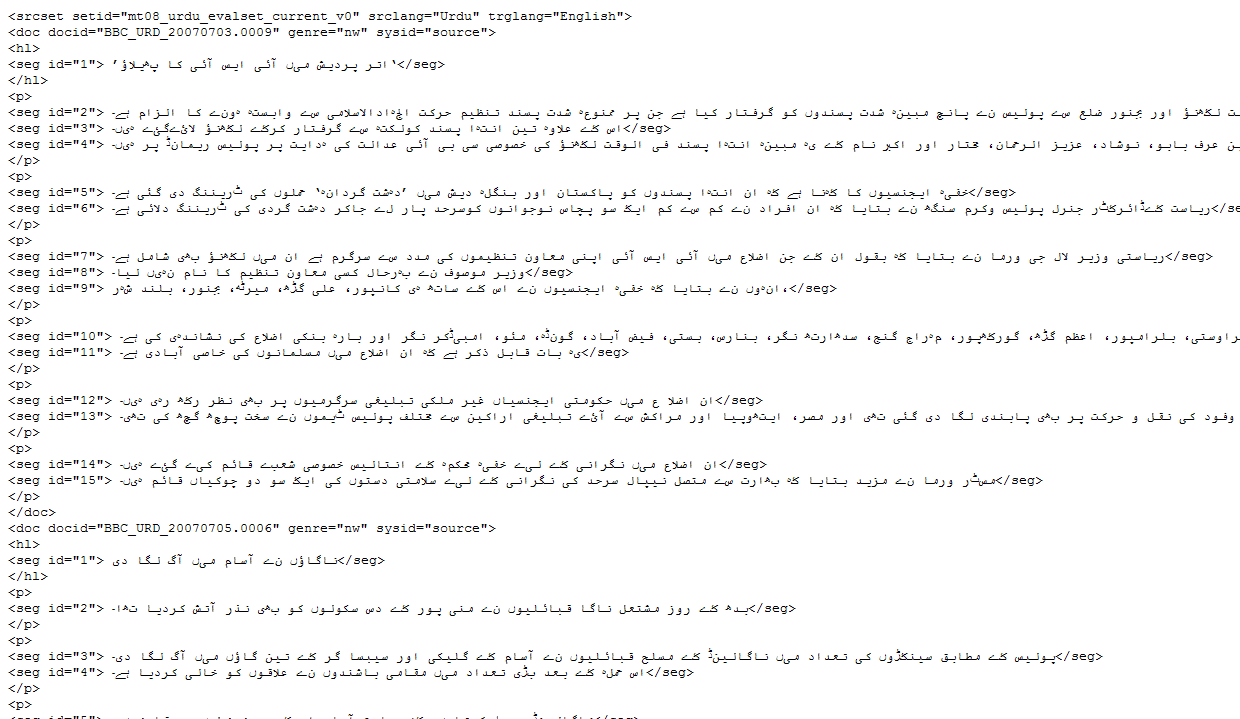
Samples
For an example of the data in this corpus, please review the sample file.
{kind=link}
Updates
No updates have been issued as of this time.