GALE Phase 1 Chinese Newsgroup Parallel Text - Part 1
| Item Name: | GALE Phase 1 Chinese Newsgroup Parallel Text - Part 1 |
| Author(s): | Xiaoyi Ma, Stephanie Strassel |
| LDC Catalog No.: | LDC2009T15 |
| ISBN: | 1-58563-517-0 |
| ISLRN: | 219-593-002-727-9 |
| DOI: | https://doi.org/10.35111/zj66-b293 |
| Release Date: | June 18, 2009 |
| Member Year(s): | 2009 |
| DCMI Type(s): | Text |
| Data Source(s): | newsgroups |
| Project(s): | GALE |
| Application(s): | machine translation |
| Language(s): | English, Mandarin Chinese, Chinese |
| Language ID(s): | eng, cmn, zho |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2009T15 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Ma, Xiaoyi, and Stephanie Strassel. GALE Phase 1 Chinese Newsgroup Parallel Text - Part 1 LDC2009T15. Web Download. Philadelphia: Linguistic Data Consortium, 2009. |
| Related Works: | View |
Introduction
GALE Phase 1 Chinese Newsgroup Parallel Text - Part 1 was prepared by LDC and contains 240,000 characters (112 files) of Chinese newsgroup text and its translation selected from twenty-five sources. Newsgroups consist of posts to electronic bulletin boards, Usenet newsgroups, discussion groups and similar forums. This release was used as training data in Phase 1 (year 1) of the DARPA-funded GALE program. .
Source Data
Preparating the source data involved four stages of work: data scouting, data harvesting, formating, and data selection.
Data scouting involved manually searching the web for suitable newsgroup text. Data scouts were assigned particular topics and genres along with a production target in order to focus their web search. Formal annotation guidelines and a customized annotation toolkit helped data scouts to manage the search process and to track progress.
Data scouts logged their decisions about potential text of interest (sites, threads and posts) to a database. A nightly process queried the annotation database and harvested all designated URLs. Whenever possible, the entire site was downloaded, not just the individual thread or post located by the data scout.
Once the text was downloaded, its format was standardized (by running various scripts) so that the data could be more easily integrated into downstream annotation processes. Original-format versions of each document were also preserved. Typically, a new script was required for each new domain name that was identified. After scripts were run, an optional manual process corrected any remaining formatting problems.
The selected documents were then reviewed for content-suitability using a semi-automatic process. A statistical approach was used to rank a document's relevance to a set of already-selected documents labeled as "good." An annotator then reviewed the list of relevance-ranked documents and selected those which were suitable for a particular annotation task or for annotation in general. These newly-judged documents in turn provided additional input for the generation of new ranked lists.
Manual sentence unit/segment (SU) annotation.was also performed on a subset of files following LDC's Quick Rich Transcription specification. Three types of end of sentence SU were identified: statement SU, question SU and incomplete SU.
Translation
After files were selected, they were reformatted into a human-readable translation format, and the files were then assigned to professional translators for careful translation. Translators followed GALE Translation guidelines which describe the makeup of the translation team, the source data format, the translation data format, best practices for translating certain linguistic features (such as names and speech disfluencies), and quality control procedures applied to completed translations.
TDF Format
All final data are in Tab Delimited Format (TDF). TDF is compatible with other transcription formats, such as the Transcriber format and AG format, and it is easy to process.
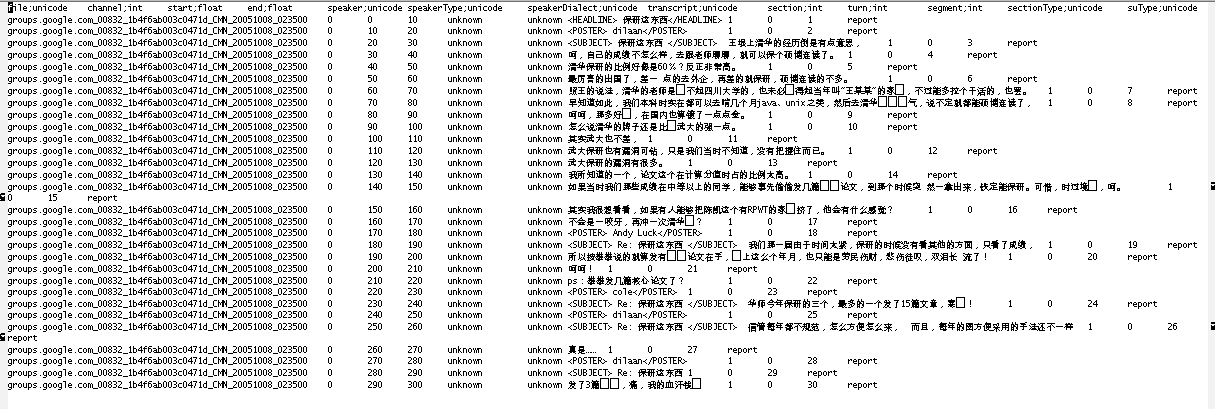
Each line of a TDF file corresponds to a speech segment and contains 13 tab delimited fields:
| field | data_type | |
| 1 | file | unicode |
| 2 | channel | int |
| 3 | start | float |
| 4 | end | float |
| 5 | speaker | unicode |
| 6 | speakerType | unicode |
| 7 | speakerDialect | unicode |
| 8 | transcript | unicode |
| 9 | section | int |
| 10 | turn | int |
| 11 | segment | int |
| 12 | sectionType | unicode |
| 13 | suType | unicode |
A source TDF file and its translation are the same except that the transcript in the source TDF is replaced by its English translation.
Some fields are inapplicable to newsgroup text. Those include the channel, start time, end time and speaker dialect fields. These fields are either empty or contain values as a placeholder.Encoding
All data are encoded in UTF8.
Sponsorship
This work was supported in part by the Defense Advanced Research Projects Agency, GALE Program Grant No. HR0011-06-1-0003. The content of this publication does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.
{kind=link}
{kind=link}