2006 CoNLL Shared Task - Arabic & Czech
| Item Name: | 2006 CoNLL Shared Task - Arabic & Czech |
| Author(s): | Charles University |
| LDC Catalog No.: | LDC2015T12 |
| ISBN: | 1-58563-718-1 |
| ISLRN: | 798-485-294-792-1 |
| DOI: | https://doi.org/10.35111/9ez4-wy88 |
| Release Date: | June 15, 2015 |
| Member Year(s): | 2015 |
| DCMI Type(s): | Text |
| Data Source(s): | newswire, journal articles, news magazine |
| Project(s): | CoNLL |
| Application(s): | syntactic parsing |
| Language(s): | Czech, Standard Arabic |
| Language ID(s): | ces, arb |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2015T12 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Charles University. 2006 CoNLL Shared Task - Arabic & Czech LDC2015T12. Web Download. Philadelphia: Linguistic Data Consortium, 2015. |
| Related Works: | View |
Introduction
2006 CoNLL Shared Task - Arabic & Czech consists of Arabic and Czech dependency treebanks used as part of the CoNLL 2006 shared task on multi-lingual dependency parsing.
LDC also released the following 2006 & 2007 CoNLL Shared Task corpora:
- 2007 CoNLL Shared Task - Basque, Catalan, Czech & Turkish (LDC2018T06)
- 2007 CoNLL Shared Task - Greek, Hungarian & Italian (LDC2018T07)
- 2007 CoNLL Shared Task - Basque, Catalan, Czech & Turkish (LDC2018T06)
- 2006 CoNLL Shared Task - Ten Languages (LDC2015T11)
This corpus is cross listed with ELRA as ELRA-W0087.
The Conference on Computational Natural Language Learning (CoNLL) is accompanied every year by a shared task intended to promote natural language processing applications and evaluate them in a standard setting. In 2006, the shared task was devoted to the parsing of syntactic dependencies using corpora from up to thirteen languages. The task aimed to define and extend the then-current state of the art in dependency parsing, a technology that complemented previous tasks by producing a different kind of syntactic description of input text. More information about the 2006 shared task is available on the CoNLL-X web page.
LDC has released data sets from other CoNLL shared tasks. 2008 CoNLL Shared Task Data contains the English material used in the 2008 shared task which focused on English, employed a unified dependency-based formalism and merged the tasks of syntactic dependency parsing, identifying semantic arguments and labeling them with semantic roles. 2009 CoNLL Shared Task Data Parts 1 and 2 consists of the English, Catalan, Chinese, Czech, German and Spanish resources used in the 2009 task which included a comparison of time and space complexity based on participants' input and learning curve comparison for languages with large datasets.
LDC has also released the following CoNLL Shared Task data sets:
- 2006 CoNLL Shared Task - Ten Languages (LDC2015T11)
- 2008 CoNLL Shared Task Data (LDC2009T12)
- 2009 CoNLL Shared Task Part 1 (LDC2012T03)
- 2009 CoNLL Shared Task Part 2 (LDC2012T04)
- 2015-2016 CoNLL Shared Task (LDC2017T13)
Data
The source data in this release consists principally of news and journal texts. The individual data sets are subsets of the following:
Samples
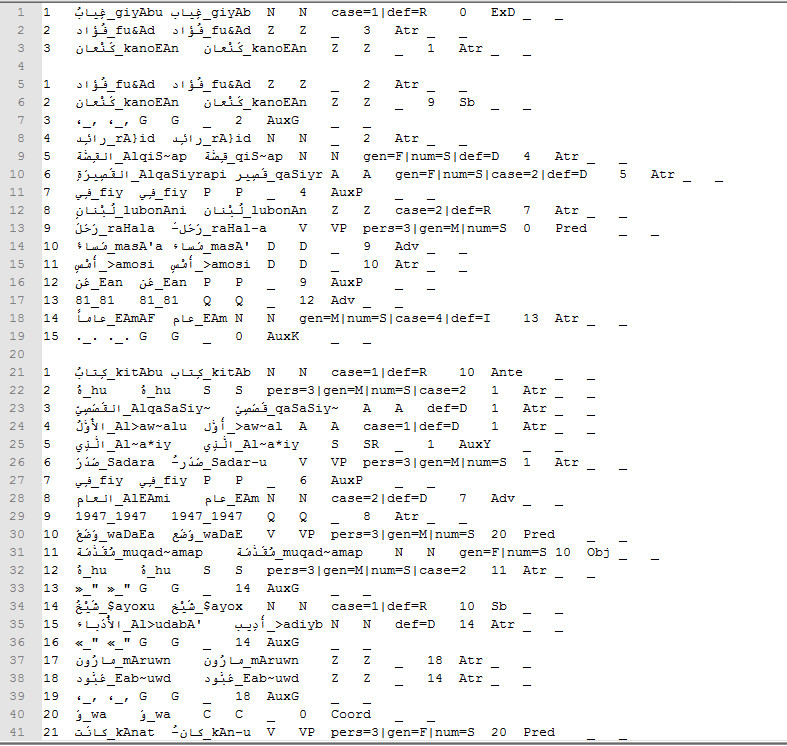
Please view these Czech and Arabic samples.
{kind=link}
{kind=link}
Updates
None at this time.