Prague Arabic Dependency Treebank 1.0
| Item Name: | Prague Arabic Dependency Treebank 1.0 |
| Author(s): | Jan Hajič, Otakar Smrz, Petr Zemanek, Petr Pajas, Jan Snaidauf, Emanuel Beska, Jakub Kracmar, Kamila Hassanova |
| LDC Catalog No.: | LDC2004T23 |
| ISBN: | ISBN 1-58563-319-4 |
| ISLRN: | 034-001-778-929-8 |
| DOI: | https://doi.org/10.35111/pn7r-7q63 |
| Release Date: | November 19, 2004 |
| Member Year(s): | 2004 |
| DCMI Type(s): | Text |
| Data Source(s): | newswire |
| Project(s): | GALE, TIDES |
| Application(s): | cross-lingual information retrieval, information extraction, information retrieval, language modeling, language teaching, machine translation, parsing, tagging |
| Language(s): | Standard Arabic |
| Language ID(s): | arb |
| License(s): | Prague Arabic Dependency Treebank 1.0 |
| Online Documentation: | LDC2004T23 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Hajič, Jan , et al. Prague Arabic Dependency Treebank 1.0 LDC2004T23. Web Download. Philadelphia: Linguistic Data Consortium, 2004. |
| Related Works: | View |
Introduction
Prague Arabic Dependency Treebank (PADT) 1.0 was developed by the Center for Computational Linguistics, the Institute of Formal and Applied Linguistics, and the Institute of Comparative Linguistics, Charles University in Prague, and consists of approximately 212,500 tokens of Modern Standard Arabic with multi-level linguistic annotations. It also provides a variety of unique software implementations designed for general use in Natural Language Processing (NLP).
The PADT project might be summarized as an open-ended activity resting in multi-level annotation of Arabic language resources in line with the theory of Functional Generative Description. The project is a younger sibling to Prague Dependency Treebank for Czech, and is maintained in co-operation with the Linguistic Data Consortium (LDC), who release non-annotated corpora of Arabic newswire and developed an independent Arabic Treebank.
Data
The corpus of PADT 1.0 consists of morphologically and analytically annotated newswire texts of Modern Standard Arabic, which originate from the Arabic Gigaword (LDC2003T12) and the plain data of Arabic Treebank: Part 1 v 2.0 (LDC2003T06) and Arabic Treebank: Part 2 v 2.0 (LDC2004T02).
The PADT 1.0 distribution comprises over 113,500 tokens of data annotated analytically and provided with the disambiguated morphological information. In addition, the release includes complete annotations of MorphoTrees resulting in more than 148,000 tokens, 49,000 of which have received the analytical processing. The contents are further divided into data sets as indicated in the table.
In the table, tokens represent the number of syntactic units that are annotated [A] analytically and [M] within MorphoTrees. Approximate ratios of tokens per paragraph and tokens per document come in the next columns, distinguishing the two types of annotation. The sets of selected documents could cover only a couple of days of the specified period of time.
| Data Set | [A] Tokens [M] | Tokens/Para | Tokens/Doc | Original Data Provider | News Period | Related Corpora | |
|---|---|---|---|---|---|---|---|
| AFP | 13,000 | N/A | 34.6 [N/A] | 260 [N/A] | Agence France Presse | July 2000 | Penn ATB Part 1 |
| UMH | 38,500 | N/A | 43.6 [N/A] | 290 [N/A] | Ummah Press Service | Spring 2002 | Penn ATB Part 2 |
| XIN | 13,500 | N/A | 31.2 [N/A] | 155 [N/A] | Xinhua News Agency | May 2003 | Arabic Gigaword |
| ALH | 10,000 | 73,500 | 47.0 [47.8] | 405 [405] | Al Hayat News Agency | September 2001 | Arabic Gigaword |
| ANN | 12,500 | 25,500 | 60.3 [50.3] | 740 [630] | An Nahar News Agency | November 2002 | Arabic Gigaword |
| XIA | 26,500 | 49,500 | 29.7 [25.9] | 235 [205] | Xinhua News Agency | May 2003 | Arabic Gigaword |
Samples
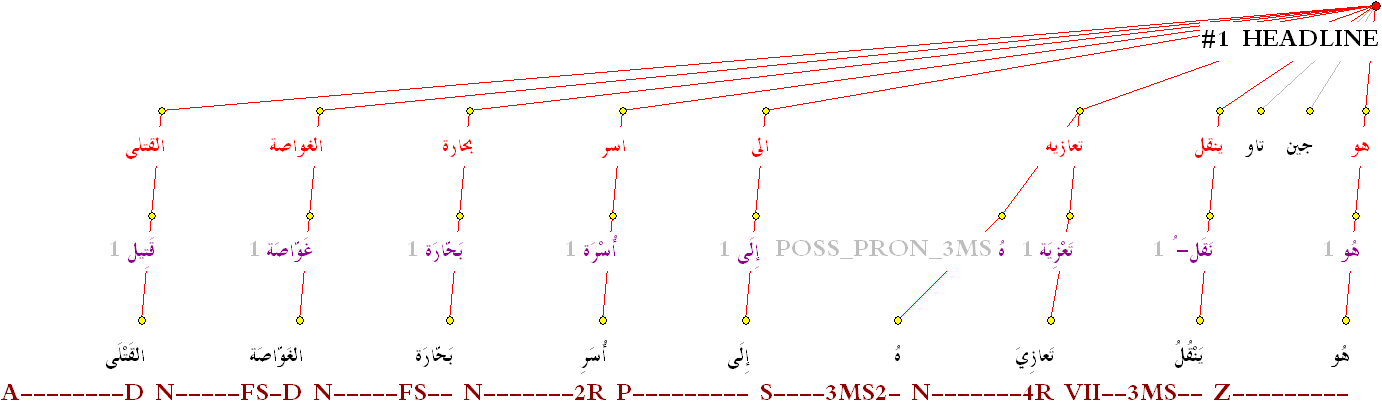
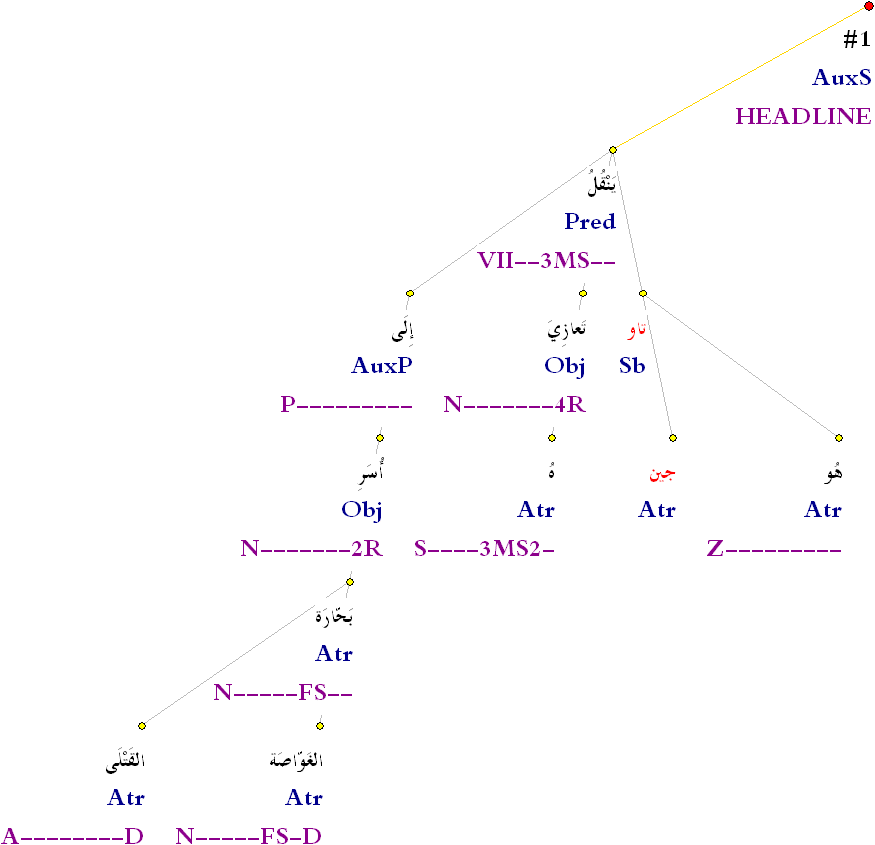
For examples of the data in this corpus, please view this paragraph morphology tree (GIF) and this new analytical rendering style (GIF).
{kind=link}
{kind=link}
Support
PADT 1.0 was supported by the Ministry of Education of the Czech Republic, projects LN00A063 and MSM113200006, and by the Grant Agency of the Czech Republic, project 405/02/0823.
Updates
Updates or bug fixes may be available in the LDC catalog entry for this corpus, or at the PADT website.
Your questions and suggestions are welcome at padt (at) ckl (dot) mff (dot) cuni (dot) cz.