Arabic Treebank: Part 3 v 3.2
| Item Name: | Arabic Treebank: Part 3 v 3.2 |
| Author(s): | Mohamed Maamouri, Ann Bies, Seth Kulick, Sondos Krouna, Fatma Gaddeche, Wajdi Zaghouani |
| LDC Catalog No.: | LDC2010T08 |
| ISBN: | 1-58563-544-8 |
| ISLRN: | 770-467-034-042-0 |
| DOI: | https://doi.org/10.35111/g7a8-ez09 |
| Release Date: | April 19, 2010 |
| Member Year(s): | 2010 |
| DCMI Type(s): | Text |
| Data Source(s): | newswire |
| Application(s): | automatic content extraction, cross-lingual information retrieval, information detection |
| Language(s): | Standard Arabic, Arabic |
| Language ID(s): | arb, ara |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2010T08 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Maamouri, Mohamed, et al. Arabic Treebank: Part 3 v 3.2 LDC2010T08. Web Download. Philadelphia: Linguistic Data Consortium, 2010. |
| Related Works: | View |
Introduction
Arabic Treebank: Part 3 (ATB3) v 3.2 was developed at the Linguistic Data Consortium (LDC). It consists of 599 distinct newswire stories from the Lebanese publication An Nahar with part-of-speech (POS), morphology, gloss and syntactic treebank annotation in accordance with the Penn Arabic Treebank (PATB) Guidelines developed in 2008 and 2009. This release represents a significant revision of LDCs previous ATB3 publications: Arabic Treebank: Part 3 v 1.0 LDC2004T11 and Arabic Treebank: Part 3 (full corpus) v 2.0 (MPG + Syntactic Analysis LDC2005T20.
The ongoing PATB project supports research in Arabic-language natural language processing and human language technology development. The methodology and work leading to the release of this publication are described in detail in the documentation accompanying this corpus and in two research papers, Enhancing the Arabic Treebank: A Collaborative Effort toward New Annotation Guidelines and Consistent and Flexible Integration of Morphological Annotation in the Arabic Treebank.
Data
ATB3 v 3.2 contains a total of 339,710 tokens before clitics are split, and 402,291 tokens after clitics are separated for the treebank annotation. This release includes all files that were previously made available to the DARPA GALE program community (Arabic Treebank Part 3 - Version 3.1, LDC2008E22). A number of inconsistencies in the 3.1 release data have been corrected here. These include changes to certain POS tags with the resulting tree changes. As a result, additional clitics have been separated, and some previously incorrectly split tokens have now been merged.
One file from ATB3 v 2.0, ANN20020715.0063, has been removed from this corpus as that text is an exact duplicate of another file in this release (ANN20020715.0018). This reduces the number of files from 600 files in ATB3 v 2.0 to 599 files in ATB 3 v 3.2.
Sponsorship
This work was supported in part by the Defense Advanced Research Projects Agency, GALE Program Grant No. HR0011-06-1-0003. The content of this publication does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.
Sample
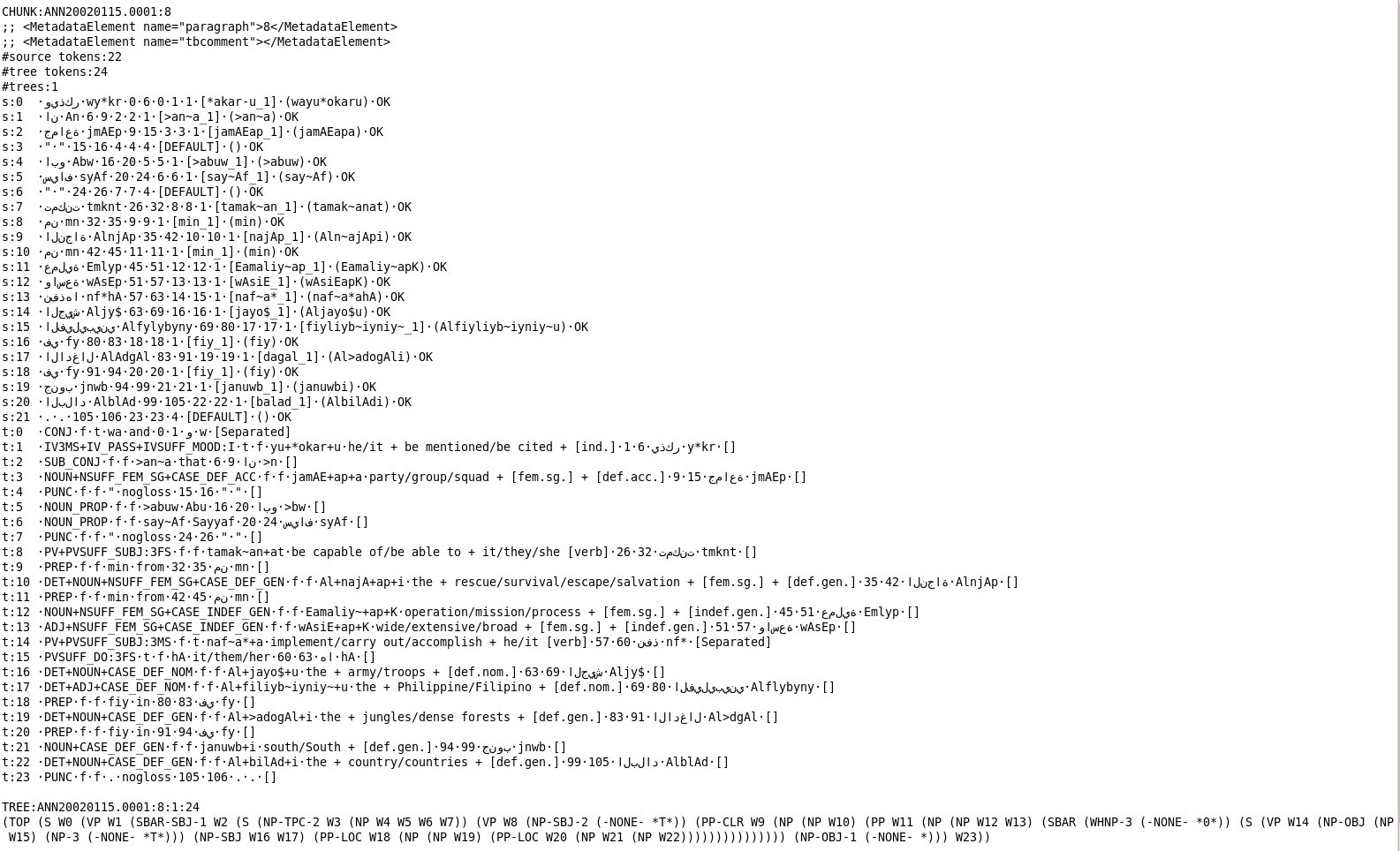
The included data are available in many different formats and files, as described in detail in the corpus documentation. The following is a screenshot excerpt taken from one of the new integrated data files: sample.
{kind=link}