GALE Phase 2 Chinese Broadcast Conversation Parallel Text Part 2
| Item Name: | GALE Phase 2 Chinese Broadcast Conversation Parallel Text Part 2 |
| Author(s): | Lauren Friedman, Hubert Jin, Song Chen, Gary Krug, Stephanie Strassel |
| LDC Catalog No.: | LDC2013T16 |
| ISBN: | 1-58563-650-9 |
| ISLRN: | 533-010-199-301-1 |
| DOI: | https://doi.org/10.35111/bd73-0j59 |
| Release Date: | August 19, 2013 |
| Member Year(s): | 2013 |
| DCMI Type(s): | Text |
| Data Source(s): | broadcast conversation |
| Project(s): | GALE |
| Application(s): | machine translation |
| Language(s): | English, Mandarin Chinese, Chinese |
| Language ID(s): | eng, cmn, zho |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2013T16 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Friedman, Lauren, et al. GALE Phase 2 Chinese Broadcast Conversation Parallel Text Part 2 LDC2013T16. Web Download. Philadelphia: Linguistic Data Consortium, 2013. |
| Related Works: | View |
Introduction
GALE Phase 2 Chinese Broadcast Conversation Parallel Text Part 2 was developed by the Linguistic Data Consortium (LDC). Along with other corpora, the parallel text in this release comprised training data for Phase 2 of the DARPA GALE (Global Autonomous Language Exploitation) Program. This corpus contains Chinese source text and corresponding English translations selected from broadcast conversation (BC) data collected by LDC in 2005-2007 and transcribed by LDC or under its direction.
LDC has also released GALE Phase 2 Chinese Broadcast Conversation Parallel Text Part 1 (LDC2013T11).
Data
This release includes 20 source-translation document pairs, comprising 152,894 characters of Chinese source text and its English translation. Data is drawn from six distinct Chinese programs broadcast in 2005-2007 from Phoenix TV, a Hong Kong-based satellite television station. Broadcast conversation programming is generally more interactive than traditional news broadcasts and includes talk shows, interviews, call-in programs and roundtable discussions. The programs in this release focus on current events topics.
The data was transcribed by LDC staff and/or transcription vendors under contract to LDC in accordance with Quick Rich Transcription guidelines developed by LDC. Transcribers indicated sentence boundaries in addition to transcribing the text. Data was manually selected for translation according to several criteria, including linguistic features, transcription features and topic features. The transcribed and segmented files were then reformatted into a human-readable translation format and assigned to translation vendors. Translators followed LDCs Chinese to English translation guidelines. Bilingual LDC staff performed quality control procedures on the completed translations.
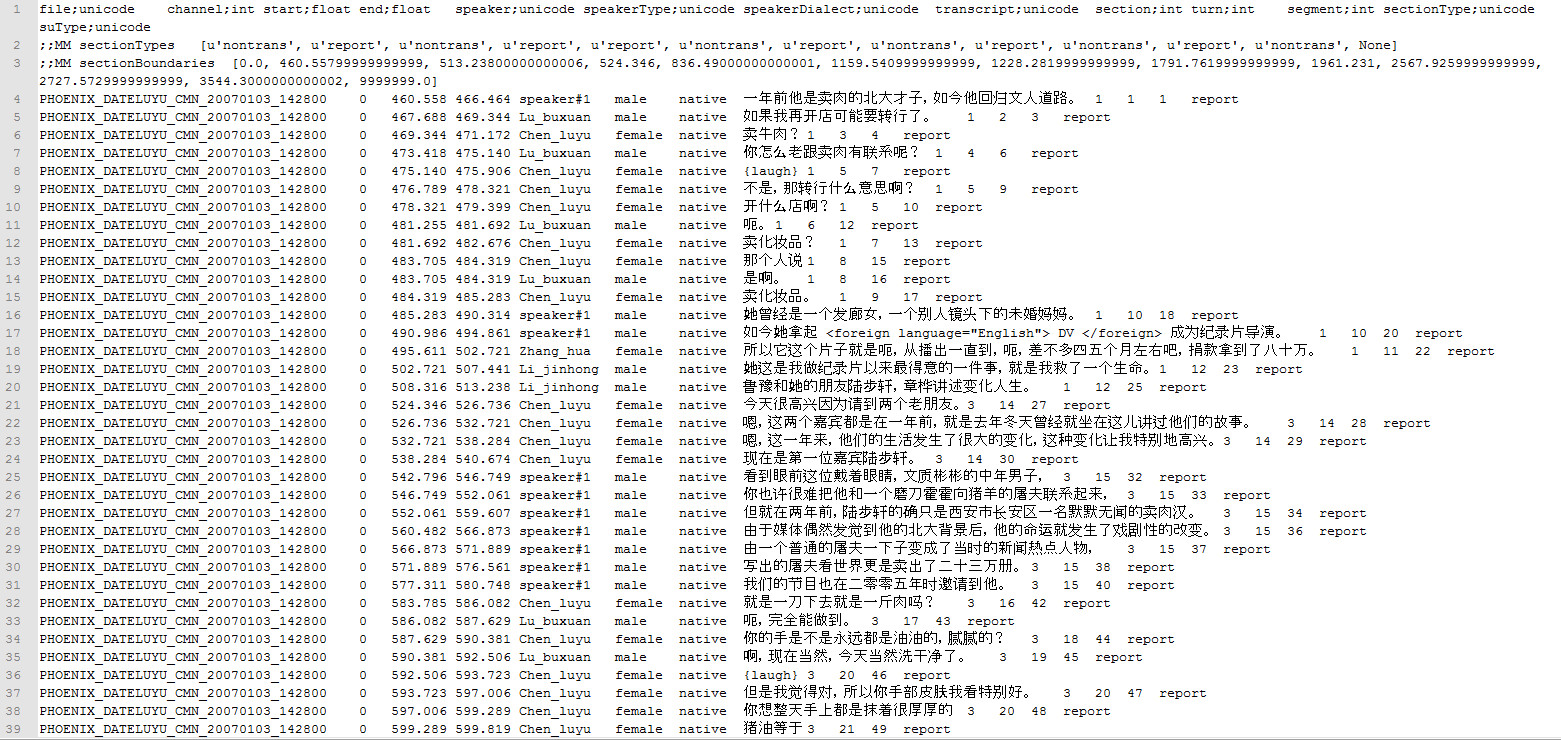
Source data and translations are distributed in TDF format. TDF files are tab-delimited files containing one segment of text along with meta information about that segment. Each field in the TDF file is described in TDF_format.text. All data are encoded in UTF-8.
Samples
Please view this Chinese source sample and English translation sample.
{kind=link}
Updates
None at this time.
Acknowledgement
This work was supported in part by the Defense Advanced Research Projects Agency, GALE Program Grant No. HR0011-06-1-0003. The content of this publication does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.