Arabic Newswire English Translation Collection
| Item Name: | Arabic Newswire English Translation Collection |
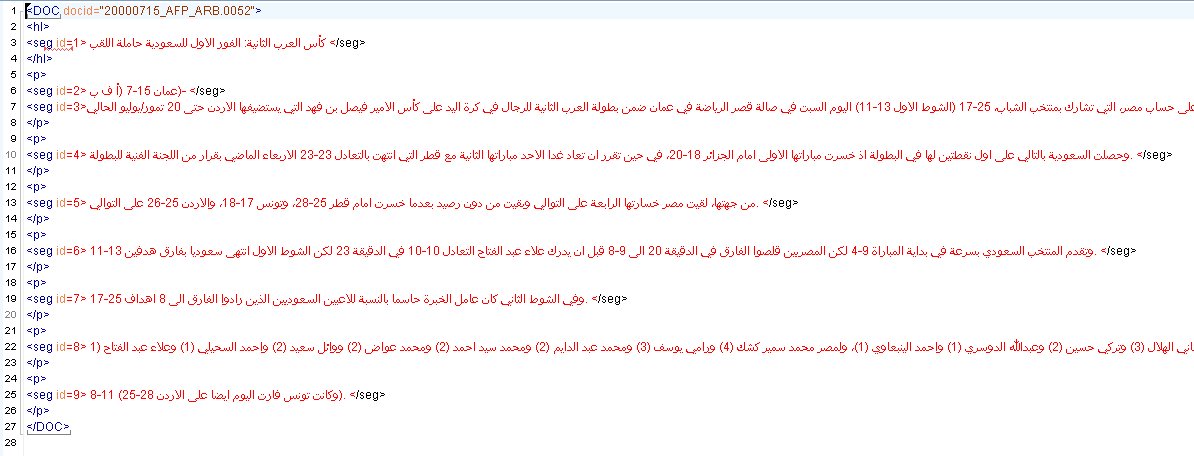
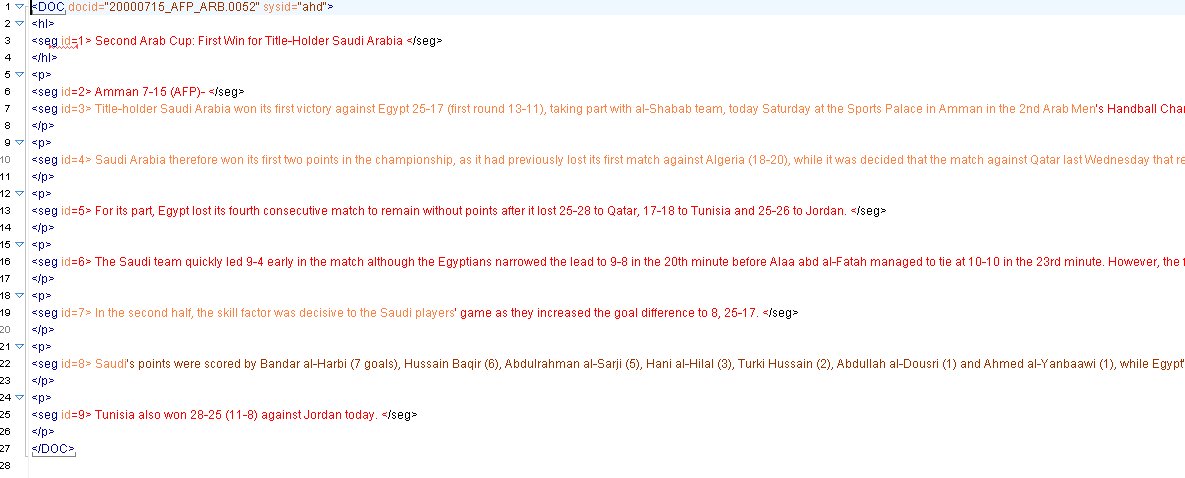
| Author(s): | Xiaoyi Ma, Dalal Zakhary |
| LDC Catalog No.: | LDC2009T22 |
| ISBN: | 1-58563-521-9 |
| ISLRN: | 677-375-027-082-6 |
| DOI: | https://doi.org/10.35111/ehq4-xc75 |
| Release Date: | August 18, 2009 |
| Member Year(s): | 2009 |
| DCMI Type(s): | Text |
| Data Source(s): | newswire |
| Application(s): | syntactic parsing, natural language processing |
| Language(s): | English, Standard Arabic, Arabic |
| Language ID(s): | eng, arb, ara |
| License(s): |
LDC User Agreement for Non-Members |
| Online Documentation: | LDC2009T22 Documents |
| Licensing Instructions: | Subscription & Standard Members, and Non-Members |
| Citation: | Ma, Xiaoyi, and Dalal Zakhary. Arabic Newswire English Translation Collection LDC2009T22. Web Download. Philadelphia: Linguistic Data Consortium, 2009. |
| Related Works: | View |
Introduction
Arabic English Newswire Translation Collection was developed by the Linguistic Data Consortium (LDC) and consists of approximately 550,000 words of Arabic newswire text and its English translation from Agence France Presse (France), An Nahar (Lebanon) and Assabah (Tunisia).
The source Arabic text in this release is contained in LDC's Arabic Treebank series, specifically, Part 1 (Part 1 v. 2.0; Part 1 v. 3.0), Part 3 (Part 3 v. 1.0; Part 3 v. 2.0) and Part 4 (Part 4 v. 1.0). A subset of Agence France Presse (AFP) source text from Arabic Treebank: Part 1 v. 2.0 was previously translated and released by LDC in Arabic Treebank: Part 1 - 10K-word English Translation, LDC2003T07. Note the 49 translations for this AFP subset are not included in this release, resulting in a total 1,682 translations for the 1,731 source stories.
The English translations in this corpus were provided by translation agencies using LDC's Arabic Translation Guidelines. While multiple translations agencies worked on both An Nahar and Assabah sources, for each specific document there is a single translation.
Data
The number of stories and their epochs for each source are as follows:
| AFP | 734 stories; July 2000 - November 2000 |
| An Nahar | 600 stories; January 2002 - December 2002 |
| Assabah | 397 stories; September 2004 - November 2004 |
| Total | 1731 stories |
Word count of Arabic tokens by source is shown in the following table:
| AFP | 102,564 |
| An Nahar | 299,681 |
| Assabah | 149,259 |
| Total | 551,504 |
The original source files used different encodings for the Arabic characters, including UTF8 and ASMO. SGML tags were used for marking sentence and paragraph boundaries and for annotating other information about each story. All Arabic source data was converted to UTF and most SGML tags were removed or replaced by "plain text" markers.
{kind=link}
{kind=link}